Agentic Harness Engineering: Let Harness Evolving Automatically
tldr: We open-sourced AHE (Agentic Harness Engineering), an observability stack for the automatic optimization of coding-agent harnesses. Without changing the model, on Terminal-bench 2 it pushes the coding agent’s score from 69.7 to 77.0 across iterations. It also exhibits strong cross-task and cross-model generalization.
Since the start of 2026, thanks to a string of blog posts from OpenAI, Anthropic and LangChain, and the breakout popularity of OpenClaw and Hermes Agent, Harness Engineering has become a hot topic in the LLM community. A consensus is forming: unlocking model capability and agency requires harness assistance and amplification, and we need a mature harness-engineering methodology to make it happen.
Every model has a harness design that “fits comfortably” and lets its capability shine. Meanwhile, models themselves keep iterating at breakneck pace, so developing harnesses efficiently and reliably is a top priority — and human agile development can no longer keep up with model evolution. The community has explored many directions in harness engineering and accumulated practical experience, but no one has yet answered systematically: in the harness-engineering iteration loop, which parts can be automated? How can a harness learn from experience to complete tasks more reliably and efficiently?
Jiahang Lin, I and Chengjun Pan have spent nearly half a year on this at the company and burned billions of tokens in search of best practices. What follows is what we explored and learned.
Takeaway
- The purpose of harness engineering is to open up a bidirectional context flow.
- The observability stack is the core: component observability (NexAU), experience observability (Agent Debugger), and decision observability (evidence-driven Evolve Agent).
- Fully observed autonomous search yields harnesses that surpass human design — less human prior, more autonomous search.
Harness Engineering: Three Perspectives
How should we optimize a harness? We look at this question from three perspectives.
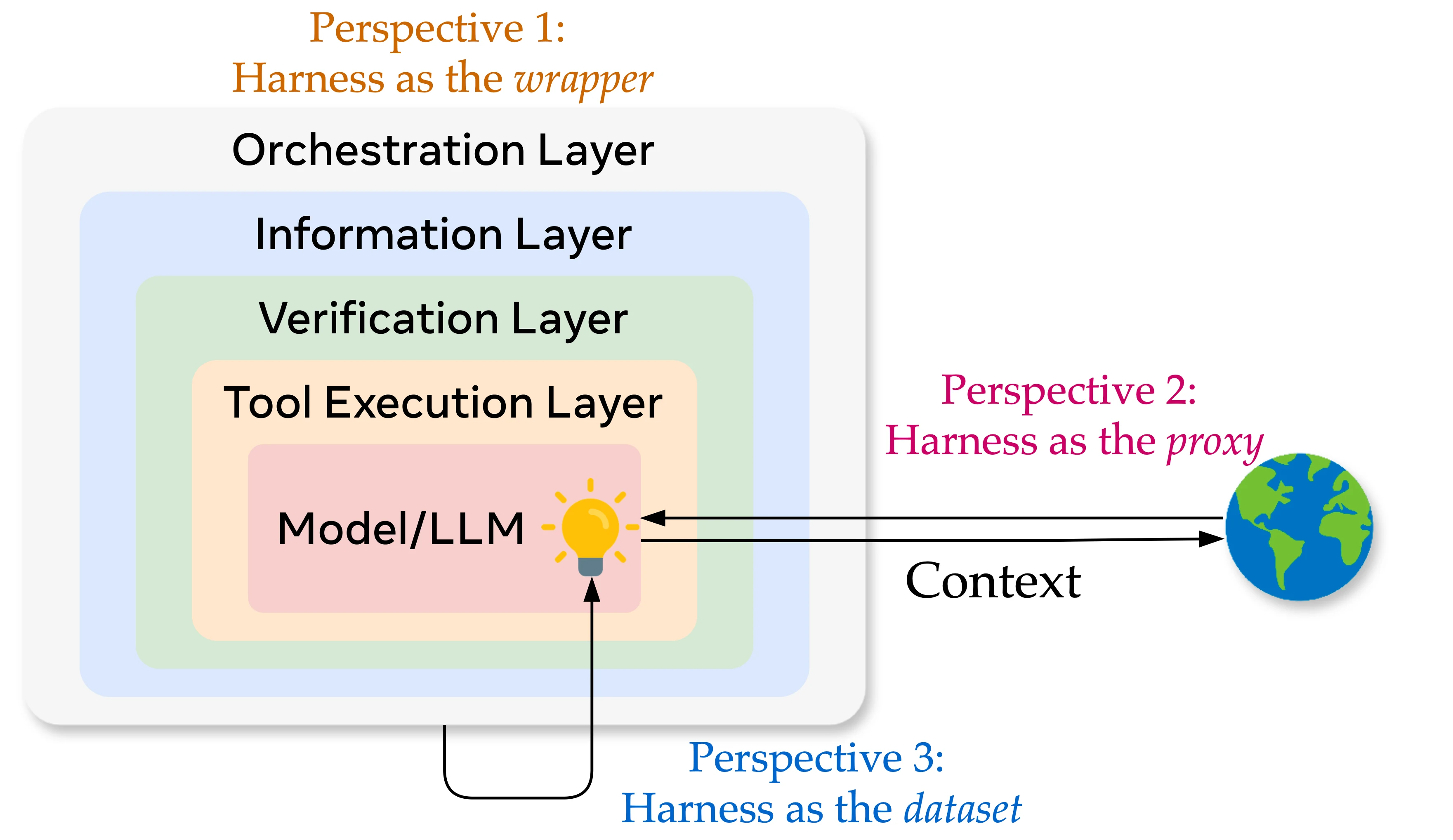
Harness as the wrapper
For long-horizon coding tasks, almost no one runs a bare model directly; instead, a stack of “attachments” is bolted on — first API tools, then MCP, skills, sandboxes. Continuous interaction with these attachments is the inevitable medium through which the model interacts with the outside world. Their numbers and forms keep growing into a leviathan that can no longer be ignored.
What is a harness? In form, a harness represents the structural increment from model to agent to agentic system; the model and the harness together form a subject that interacts with an environment. The model produces the conditional distribution over the next token — it is the source of compression, of intelligence, of uncertainty; the harness is everything deterministic wrapped around it: system prompt, tool definitions and implementations, middleware hooks, skill documents, sub-agent orchestration, long-term memory, logging and observability. Together they handle tool invocation, context retrieval, sandbox isolation, logical orchestration, and feedback/reflection. When an agent needs to run reliably over the long horizon and iterate via reflection, these components are indispensable.
Decomposed further, a harness can be partitioned into an information layer (memory, context management, tools, skills), an execution layer (orchestration, sandbox, guardrails), and a feedback layer (evaluation, tracing, observability), corresponding to the three stages of agent operation. Each layer has its own engineering principles: the information layer pursues precision — progressive disclosure, higher context utilization; the execution layer handles task orchestration and management, partitioning sessions by task phase to avoid context contamination; the feedback layer closes the loop and grounds the agent so the model never repeats the same mistake. The community has already developed substantial methodology for each layer.
Harness as the proxy
Given these components, what direction should optimization take? In terms of purpose, a harness manages a bidirectional context flow between model and environment: on one side, it injects task, user intent, environment state, and external information into the model at the right moments; on the other side, it faithfully records and validates the model’s actions before handing them back to the environment for execution.
On this point, Anthropic put it well in their blog: “Good context engineering means finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome.” and “Thoughtful context engineering is essential for building capable agents.” In the past, developers had to feed prompts by hand, copy terminal outputs, and copy external documents to the model; context lived in disconnected spaces, and humans decided context composition by intuition and observation.
Hence one design goal of a harness is to make the flow of context more precise and more autonomous. On the inflow side, the harness is the user’s proxy: it crystallizes user preferences, instructions, conventions, domain knowledge, and validated good development patterns into system prompts, memory, skills, and sub-agent orchestration logic — these are user context at different granularities. On the outflow side, the harness is the environment’s proxy: the model’s response is parsed by the harness and may be intercepted/constrained ahead of time — for instance, guardrail middleware validates the action the model is about to take, effectively modeling the environment by translating env context into constraint code and preventing the model from sliding into futile exploration.
The direction for optimizing a harness is to make that context channel between model and environment as high-bandwidth, low-loss, and auditable as possible.
Harness as the datasets
Going further: how should we actually optimize the harness?
The most direct route is to optimize the components themselves — i.e., agent infra. The developer community has contributed many useful harness components for memory, context management, sandbox environments, and trajectory management, all built on serious engineering effort that makes each piece individually more efficient, secure, and reliable.
But for any specific environment, finding the optimal harness becomes a model × harness × env combinatorial optimization problem. Unlike building isolated components, there is no clean rule, no human prior that lets you nail the optimal combination in one shot. You have to develop, observe, and iterate — using fuzzy or sparse signals like trajectories and benchmark scores to repeatedly tune the nonlinear interplay among components. In this new era, no one has heroic, genius-level intuition about agents; model capabilities shift too fast, task environments shift too fast, and manual optimization is too slow.
Human attention is scarce; silicon-based life never tires. So the agent itself must participate in harness optimization. As long as the optimization objective, the action space, and the state space are presented in agent-readable form, you can plug in an agent to drive autonomous optimization. It can be claude code, it can be openclaw, whatever. As long as we make every component and every step of how the harness mediates context between model and environment transparent and observable, a continuously evolving harness is right around the corner.
This is what we’ve done. Below, we’ll walk through how we built the observability stack — declarative components, progressive disclosure, layered analysis, version control.
Before that: if you want to push harness optimization even deeper, the next layer is harness–model co-design — co-evolution of harness and model. As DeepMind Staff Engineer Philipp Schmid put it: “The harness is the dataset. Competitive advantage is now the trajectories your harness captures.” These trajectories get trained into the model’s parameters via SFT, RL, or OPD. Making the model fluent in the heterogeneous context the harness exposes requires both context learning and tool internalization — and slows context decay.
In an interview with Cat Wu (Head of Product, Claude Code), Lenny Rachitsky was told, “the model will eat your harness for breakfast.” Borrowing from Heideggerian phenomenology: today’s harness components are present-at-hand (Vorhandenheit) to the model — every use forces tool schemas, calling conventions, and risk reminders into context, and the model has to be aware they exist; once trained into weights, they become ready-to-hand (Zuhandenheit) — the model no longer needs to see them in context, just as a skilled carpenter doesn’t notice the hammer. The harness shrinks over time, leaving only what truly cannot be internalized — and by then, a new harness has already begun to gestate.
Model and harness will spiral upward, iterating on each other. That’s the next direction for harness evolution and the direction of our future work. This article focuses on the first step: how the present-at-hand harness of today can be iterated and evolved efficiently.
Note: Stanford’s meta-harness does similar work with strong results. We’re glad others are paying attention to this direction and warmly recommend reading both pieces side by side.
The Observability Stack within the Nex Ecosystem
Our starting point: we don’t write a single line of harness code by hand, nor do we directly develop any single component ourselves. Instead, we build a complete platform that lets one agent automatically optimize the harness of a target coding agent (in our setting, the optimizer and the optimized are different agents — this is not self-evolving). What infrastructure does that require?
Like all software development, harness development has phases: write components, run the agent, collect feedback. The cycle iterates and runs continuously. For an agent to take over the human’s role here, all the context produced in this loop must be observable, structured, and layered. We do not constrain the agent’s autonomous decision space with guidance; we rely solely on evaluation results, plus rich layered information that helps it modify precisely and attribute accurately.
We built a complete observability platform that records every stage in detail. Three parts:
- NexAU provides decoupled harness components, delivering component observability;
- Agent Debugger distills 10M-token-scale raw traces into layered, traceable, multi-dimensional feedback, delivering experience observability;
- Evolve Agent builds an evidence-driven, end-to-end edit chain on top of git-tracked component history and feedback, modifying components accordingly — delivering optimization-behavior observability.
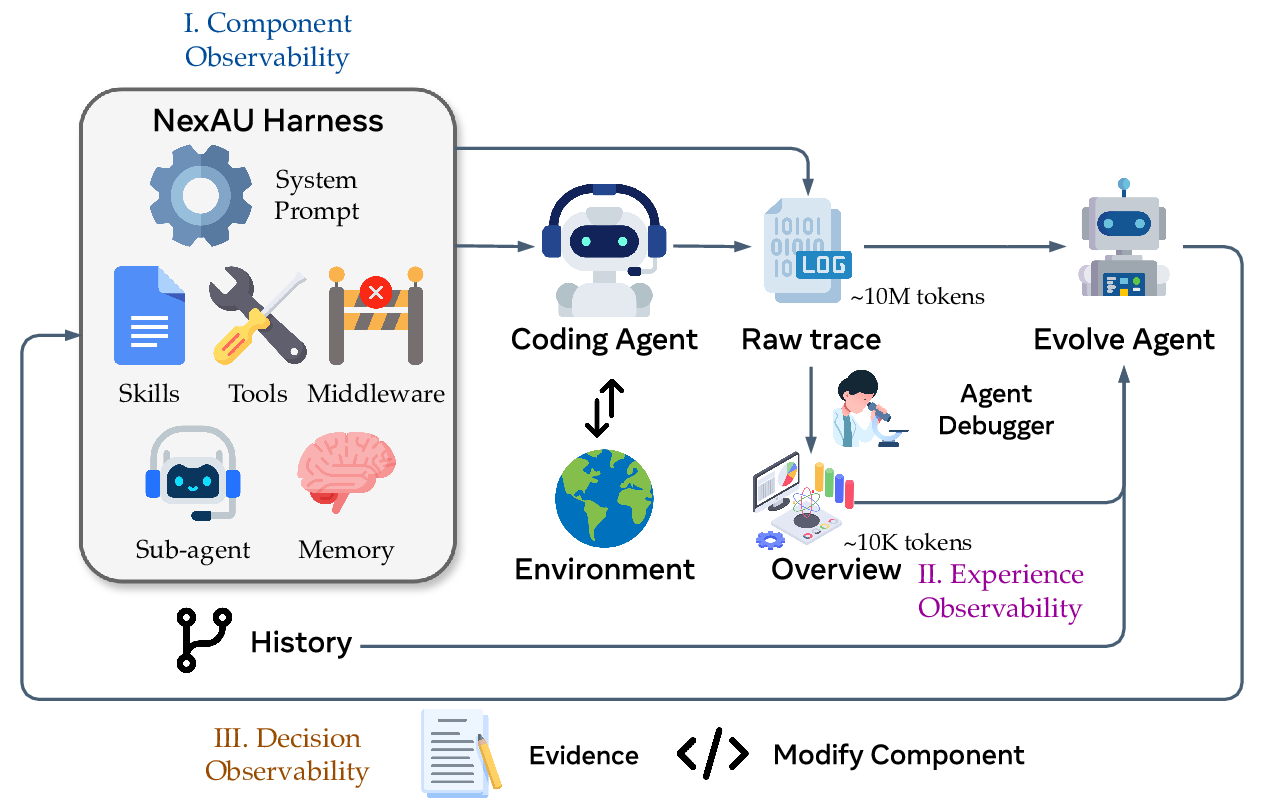
NexAU: decompose the harness into traceable components
We design our coding agent on top of the NexAU framework. NexAU’s key property is that all editable components are exposed as explicit files inside a workspace directory. Seven orthogonal component types (system prompt, tool description, tool implementation, middleware, skill, sub-agent, long-term memory) each have a clear file format and mount point. They are structurally decoupled: adding a middleware does not require touching the system prompt; adding a skill does not require touching any tool implementation.
Decoupling makes the failure-mode-to-component mapping crisp, giving the Evolve Agent a clearer action space. The workspace is tracked by git: every logical change is paired with a commit, providing file-granularity diffs and revertible history. Every step of harness evolution can be located, audited, and rolled back — and post-hoc adjudication of the previous round’s changes becomes something a machine can do.
The coding agent under optimization deliberately starts from a zero-prior, minimal form: only one run_shell_command tool, no middleware, no skills, no sub-agents. If the starting point already carries priors about the target benchmark, every subsequent component addition and every prompt rewrite would be polluted, making clean attribution of gains or regressions impossible. We don’t want a harness that only games the leaderboard or overfits to a specific benchmark — we want one with real generalization.
Agent Debugger: turn traces into consumable assets
A single rollout’s raw trace can run to hundreds of thousands of tokens, including every LLM call, every tool call, every middleware hook, every sub-agent invocation, and the eval results. A single eval round often comprises hundreds of traces. Throwing all that raw at the Evolver burns its entire context budget on reading traces, leaving almost no room for actually changing code. Raw traces are not a high-value asset by themselves.
Agent Debugger builds a layered distillation pipeline on top of raw traces: the bottom layer faithfully records all trajectories (~10M tokens); a cleaner deduplicates tool outputs; an upper-layer QA sub-agent switches prompt templates per-task based on the pass/fail distribution across k rollouts — for all-failures it asks for root cause and bias; for all-passes it asks for successful strategies, reusable patterns, and latent fragilities. Finally everything is aggregated into an overview (~10K tokens) for the Evolve Agent to consume.
The layering isn’t just compression — it is essentially progressive disclosure. The Evolver reads the overview by default; it can drill into a specific task’s analysis, and even fall back to the raw trace to verify a conclusion. This turns 10M-scale trajectory data into a concurrent, consumable, auditable observability asset.
Evolve Agent: evidence-driven component edits

The Evolve Agent operates on the observable, attributable workspace and follows the principles below to keep its own behavior observable and traceable.
Workspace-only writes. The runs directory, tracer, verifier, and LLM config are read-only; the original system prompt is explicitly marked non-deletable. This confines the Evolver’s action space to the harness and prevents it from hacking by bypassing the verifier or swapping models (e.g., by editing reasoning effort).
Evidence-driven. Before any edit, the Evolver must produce its rationale: which specific tasks failed (failure evidence), why they failed (root cause), an edit that targets the root cause directly (targeted fix), and which tasks it expects to fix plus which it might break (predicted impact). Every change is falsifiable by the next round of evaluation rather than by subjective judgment; changes deemed harmful by the Evolve Agent’s holistic review are rolled back at file granularity.
Putting it all together, each outer-loop round is six sequential stages: run the current harness on the eval → clean traces → adjudicate the previous round’s changes → Agent Debugger does attribution → Evolve Agent edits the workspace and provides evidence → commit the corresponding changes. Every round’s artifacts are archived into a structured directory, and any round’s process can be fully replayed and audited.
Experimental Setup
We iterate on Terminal Bench 2.0, a terminal-environment agent benchmark with 89 human-vetted real-world tasks spanning software engineering, sysadmin, and scientific computing. Each task runs in an isolated sandbox and is judged pass/fail by scripted tests. We use the official Terminal Bench 2.0 evaluation framework harbor for evaluation. Timeout is set to 1h (due to API rate limits), with gpt-5.4 as the iterating model and reasoning effort set to high (balancing experimental quality and efficiency). We use the open-source build of e2b as our sandbox implementation, deployed locally (thanks to the infra guys from Qijizhifeng & infraware).
To probe cross-task transfer, we picked SWE-Bench Verified — 500 human-vetted Python repository-level bug-fix tasks where the agent only has to produce a code patch, judged by the repository’s own unit tests.
Early Failure Cases
The Evolve Agent’s design went through two adjustments. Early on, we observed plenty of benchmark-overfitting behavior; pushing back against it required some effort.
Phase 1: small subsets are easy to hack
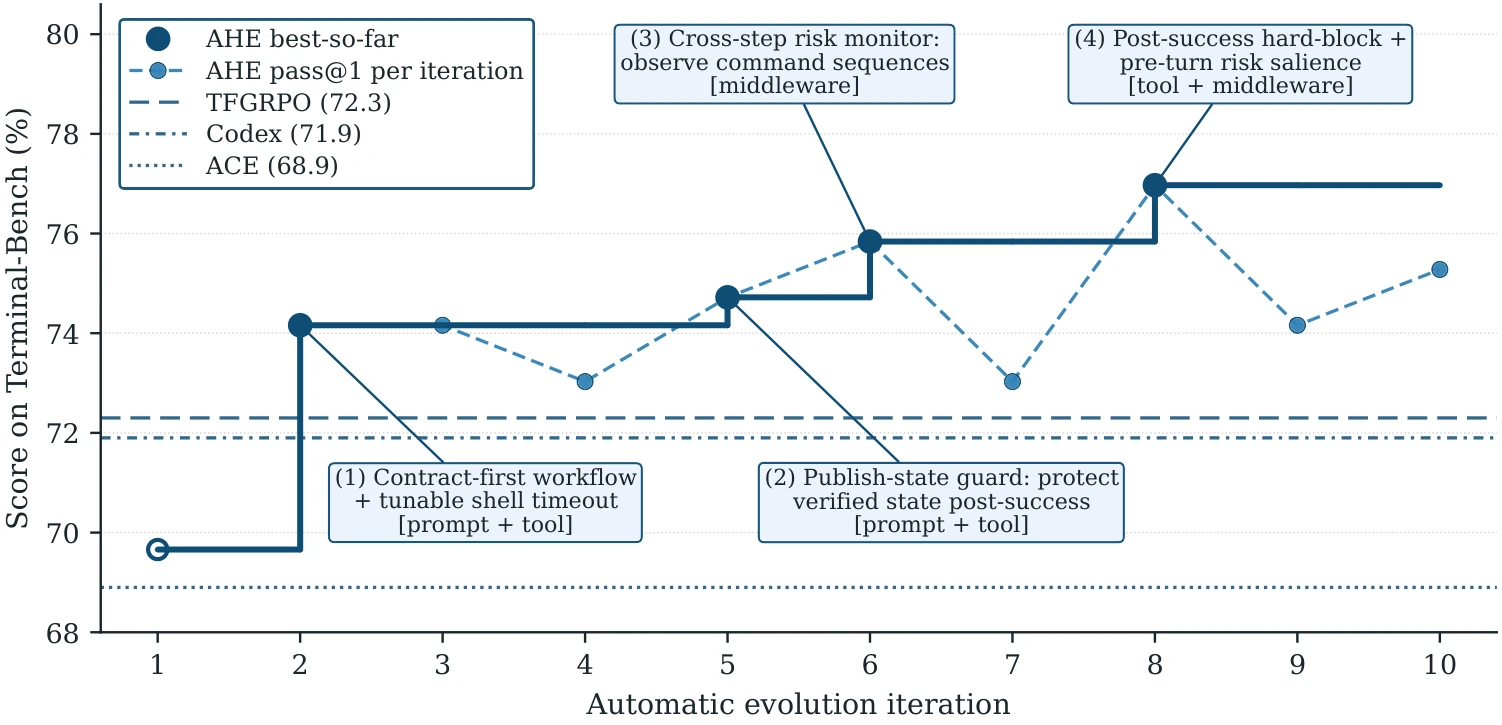
For fast iteration, we picked the harder 30 tasks from Terminal-bench 2 and ran the system on this subset for 10 rounds. Pass count oscillated between 16 and 20 — no sustained upward trend. Per-task pass/fail flips between consecutive rounds showed a fix rate of 6.7% and a regression rate of 7.7% — basically, fixing one task broke another, with an average net loss of one point per round.
Our criterion for task-specificity: does the code contain information meaningful only to specific benchmark tasks — concrete task names, domain jargon, file paths, algorithm-choice hints, etc.? Analyzing the modified components, we found that the Evolve Agent’s diagnostic reasoning, sharp down to the code level, on the 30-task subset turned straight into task-specific hacking: the final harness contained a fast-doubling heuristic for Fibonacci, splice-offset detection for Golden Gate, and a complete workflow template for Caffe.
Conclusion: small subsets give task-specific signal too much weight (one task takes up too large a fraction of the set), so the eval signal can’t suppress hacking. We needed a more honest signal.
Phase 2: human-prior behavior preferences aren’t necessarily reliable
We expanded the task set to the full 89 and added explicit methodology to the Evolve Agent’s system prompt — three principles (Safety / Creativity / Generality) and a constraint hierarchy: “Always prefer the strongest constraint level that fits. Middleware/Tool impl > Tool desc > Skill > System prompt.” Expanding the set did mitigate overfitting: regression rate dropped from 7.7% to 6.0%. The Evolver landed 78% of edits in the middleware layer; the prompt was edited only 3 times. No more obvious task-specific hacks — but the training curve plateaued at 75.3% early on and never broke through. Evolution stalled. The middleware edits the agent produced were generic but not necessarily effective (they didn’t solve the problem), and the agent collapsed onto modifying this single component type.
Conclusion: human-injected behavior priors became rigid. We shouldn’t directly tell the agent which components humans prefer to modify — that prior may simply be wrong.
Phase 3: robustness and hierarchy
We also observed: coding tasks include a lot of environment noise — model API stability, temperature, sandbox stability, and so on — so a more robust scheme is needed.
Two concrete changes.
-
At evaluation time, run each task twice (very simply, two runs at the same setting) — not to chase pass@k, but to enable partial-pass contrasting. Same task, same agent, one pass and one fail — the Evolver can diff the two traces and pinpoint the root cause. This is the highest-quality diagnostic signal we have.
-
Prioritize the agent’s context. Require the agent to read
overview.mdfirst, and the run logs only after editing middleware. Strip out all behavior guidance — delete the entire Creativity principle, the Generality contrast table, the constraint hierarchy ordering — and keep only the Evidence-Driven process requirements and the rollback-and-pivot rule.
On the same 89-task benchmark, scores climbed steadily and topped out at 77.0%, with much steadier gains. Edit distribution shifted to middleware 37% + tool 48% + prompt 10%; no single layer exceeded 50%, and the mix flexed across phases — the early rounds favored tool + prompt, with middleware coming in mid-to-late.
Takeaway
Agents derive their evolutionary drive from external feedback. For the Evolve Agent, the human’s job is not to substitute its methodological thinking but to ensure the feedback signal is high-quality and broadly covered: enlarge the task set, add rollout contrasts, pre-build analysis reports, surface run logs. With good feedback, the model finds the right evolutionary direction on its own (bitter lesson again). That is the core motivation behind our observability stack.
Evolving on Terminal-bench 2
We evaluate on the full 89 tasks of terminal-bench 2 (per-task timeout relaxed to 1 hour); all role agents share the same base model (GPT-5.4 high reasoning). We care about three things: AHE’s effectiveness, whether harness optimization overfits, and exactly which component category accumulates the value.
Main result: continuous evolution that surpasses human-designed harnesses
We picked codex-cli, also from OpenAI, as our human-optimized harness baseline. As shown in Figure 1, after 10 rounds of evolution, the pass@1 score climbs from NexAU_bash-only’s 69.7% to 77.0% — an absolute gain of +7.3 pp and a relative gain of +10.5%.
Generalization: across datasets and models
We froze the evolved harness and evaluated on SWE-bench-verified’s 500 tasks. Compared with other continuous-evolution baselines (ACE, TrainingFree-GRPO), AHE leads on both success rate and token cost. This shows the evolved harness has learned general engineering practice, not Terminal-bench-2-specific leaderboard tricks.
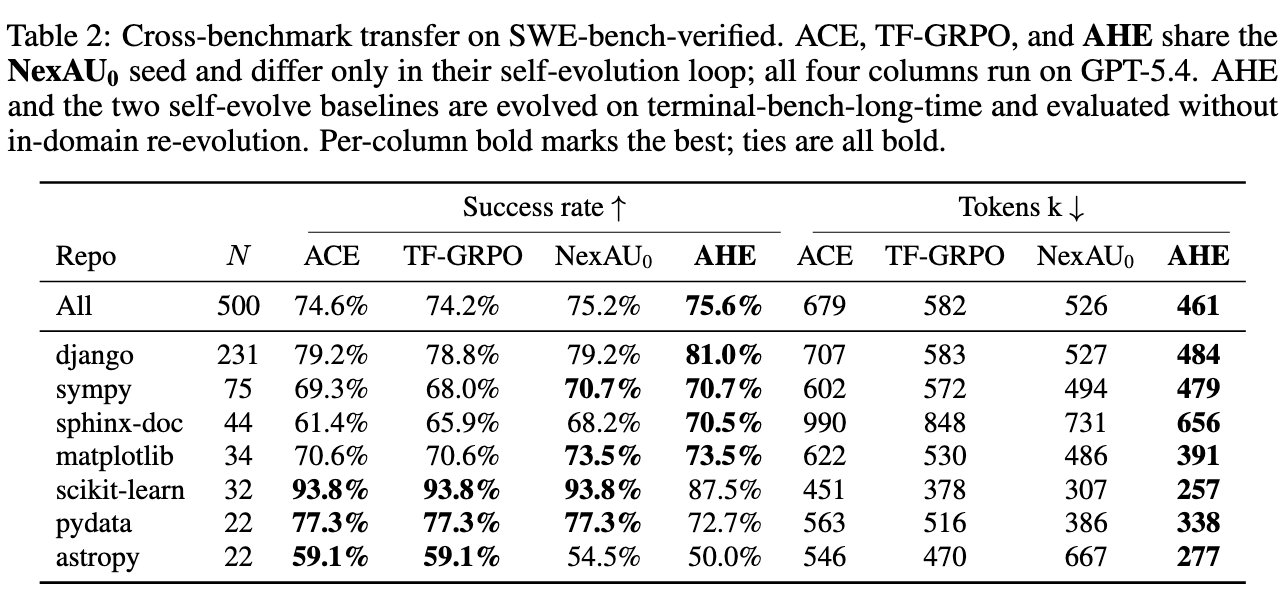
We froze the same AHE harness (evolved with gpt-5.4), swapped the base model, and re-evaluated on Terminal-bench 2 with no further evolution. We saw +5.1 pp to +10.1 pp gains across Qwen, Gemini, and Deepseek, proving that the iterated harness is not GPT-specific. It also suggests that on weaker models, the harness’s contribution is even larger:

Component transfer: where does the value accumulate?
We took the four component categories that AHE evolved (memory, tools, middleware, system prompt) and plugged each one back individually into the bash-only NexAU baseline, keeping the other three at default — measuring each category’s marginal contribution:
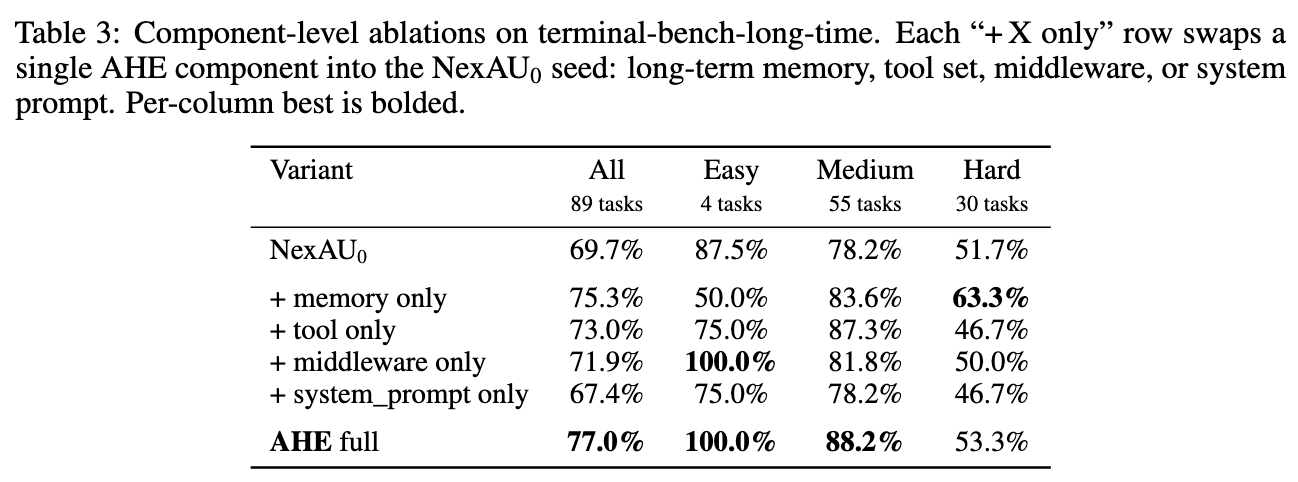
We find: memory and tools yield significant gains, while system prompt fails to transfer in isolation. Swapping in just memory recovers more than 95% of the global gain; swapping in just tools yields significant gains on Medium tasks, while swapping only the system prompt actually decreases scores. This contradicts the community reflex of “tune the prompt first.” Our reading: prompt semantics are strategic (you should do it this way), whereas memory and tool semantics are factual (here’s a reusable code snippet). Facts transfer better than strategies — preserving information while keeping generalization intact.
We analyzed the Evolve Agent’s behavior. The largest single category of context it reads is workspace code (44.9%), followed by raw trace (22.8%) and debugger report (14.1%). Of the 33 tasks where the raw trace was opened, 32 first read the corresponding debugger detail. Roughly 56% of failed tasks were edited by the Evolver after reading only the debugger root cause — without revisiting the raw trace.
In edit distribution, tool_impl + middleware together account for 76%; prompt only 13%; skill was never edited. We find that the number of files edited in a single iteration is uncorrelated with effect — heavy editing often signals agent uncertainty; small, precise edits to a few files (e.g., iter5’s introduction of a pre-action risk-assessment middleware, iter9’s introduction of a post-action verification middleware) both produced positive returns.
What’s Next?
Looking back, we’ve really done two things: build the observability stack (so the Evolve Agent can access components, traces, and feedback), and run tests on the full dataset. Methodology doesn’t need to be hand-fed by humans; give the agent a structured workspace, a clear edit interface, and high-quality feedback signals, and its behavior automatically converges toward that of a real engineer.
Once a domain can be automated by an agent, humans need to think about higher-level design. As model intelligence crosses the singularity, agents will be able to autonomously close ever-wider loops: harness optimization → constructing data or environments that compensate for their own deficits → training updated parameters → producing harder evaluation sets. Inside an exponentially accelerating process, I dare not imagine how quickly AGI will arrive.
It’s time to take the first step and let the harness evolve automatically.
Cite This Work
@misc{linAgenticHarnessEngineering2026,
title = {Agentic {{Harness Engineering}}: {{Observability-Driven Automatic Evolution}} of {{Coding-Agent Harnesses}}},
author = {Lin, Jiahang and Liu, Shichun and Pan, Chengjun and Lin, Lizhi and Dou, Shihan and Huang, Xuanjing and Yan, Hang and Han, Zhenhua and Gui, Tao},
year = 2026,
month = apr,
doi = {10.48550/arXiv.2604.25850},
url = {http://arxiv.org/abs/2604.25850}
}