Memory in the Age of AI Agents: Agent Memory Mechanisms and the Story Behind This Survey
Paper Link: https://arxiv.org/abs/2512.13564
This blog post is only an introduction; we do not expand the detailed and fully rigorous statements here. You are welcome to read the full paper via the link above.
Introduction
Without a doubt, research on LLM memory and agent memory has become one of the spotlight topics of 2025. From an ever-growing stream of academic papers, to well-known open-source projects like mem0 and MemOS, and to interviews with popular researchers such as Ilya and Shunyu Yao, memory is being repeatedly mentioned, emphasized, and proclaimed. It seems to be everywhere: emotional companionship, document analysis, scientific discovery, long-form reasoning, multi-hop QA, web tasks, GUI interaction, video generation, embodied intelligence, and more. Yet, while all these works claim to have implemented or leveraged memory to solve downstream tasks, their designs often differ drastically.
So, what exactly is memory?
This question is precisely why we wanted to write this paper: to use one unified taxonomy to bring order to the landscape. We aim to offer a perspective and a conceptual vocabulary, so that every memory-related work can be positioned on a common map—properly understood, examined, and appreciated for the role it plays in its own niche. We also hope to provide the community with a panoramic description that strengthens cohesion rather than fragmentation. Such a framework should be both compatible and forward-looking: it should seamlessly accommodate the explosion of memory papers this year, while also serving as a position paper that hints at future directions. It should also be intuitive and clear, making it easy for beginners to get started, while organizing resources and evaluations and offering guidance from theory to practice.
Because we believe: memory is indispensable to the realization of AGI.
Concept Clarification
In 2025—the year many call the “first year of agents”—what we are dealing with is agent memory. So the first challenge we must face is conceptual clarification: what is the difference in focus between agent memory and LLM memory?
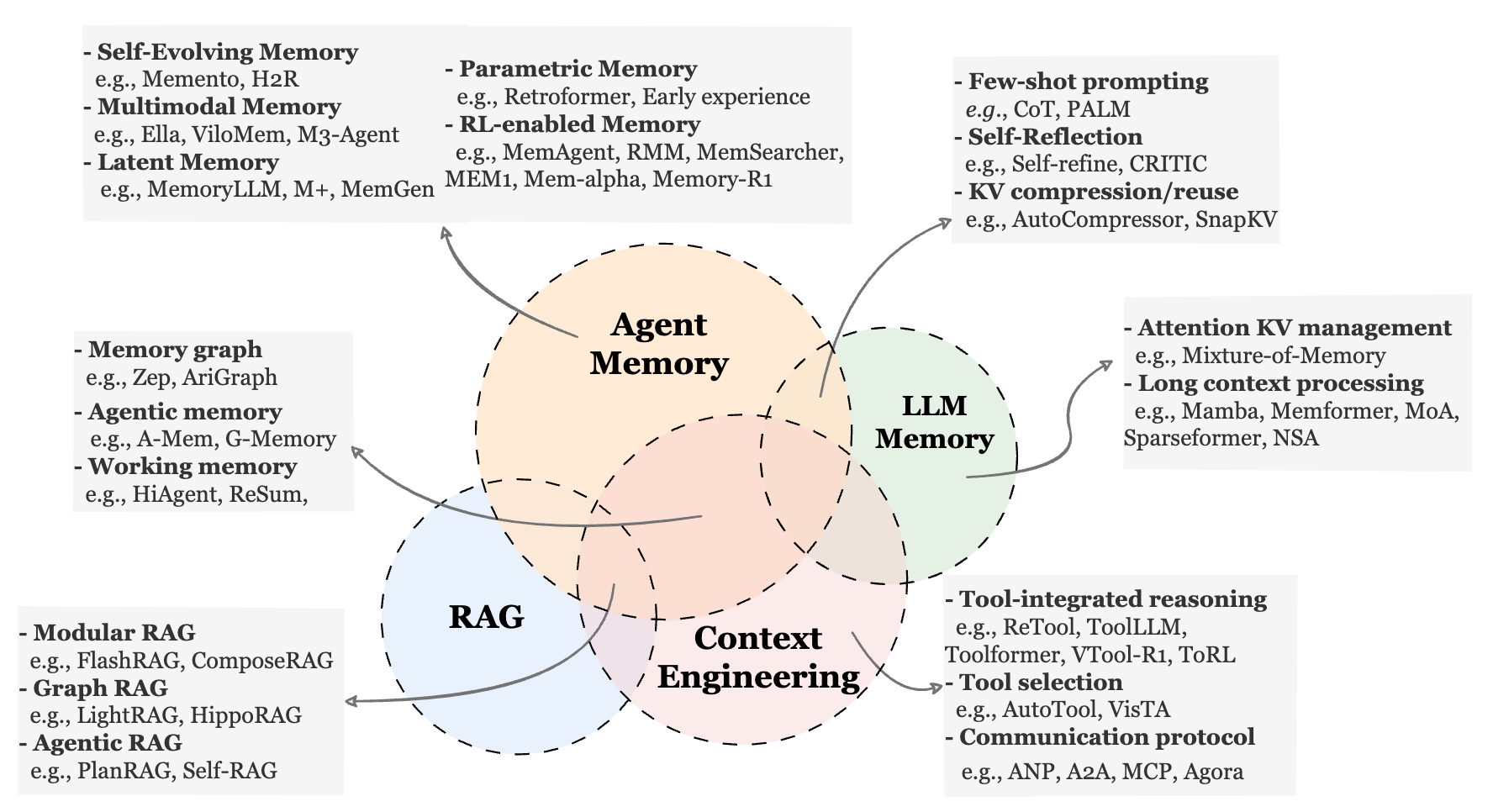
By comparing LLM memory, RAG, and context engineering, we can roughly understand them as follows: LLM memory is a research area that emerged before the agent paradigm was firmly established; RAG is a standardized methodology; and context engineering is a technical field centered on the context itself. Agent memory intersects with these areas in both application domains and research methods.
We wrote this chapter in response to a common feeling: that what memory is doing seems similar to xxx, that “isn’t this just xxx?”, that it is merely “old wine in a new bottle.” Some readers develop a bias against discussing memory itself, seeing it as storytelling or filler—“Even this can be forced into relevance?”
We do not avoid this, nor do we pretend it does not exist. We must acknowledge that overlap among these methods is objectively real, and that they are coupled and borrow from each other. Agent memory today is an expansive research topic covering multiple task domains and methodological families. It is exactly this fragmented, warlord-era landscape that creates the vague, half-understood impression among both insiders and outsiders. That is why we want to clarify things as much as possible—and use a framework to break this impasse.
We also want to set the record straight for memory. The real value of a research paper comes from a multi-dimensional, non-linear combination of key domains, core problems, elegant methods, solid experiments, careful analysis, and deep insights—ultimately reflected in genuine market signals such as discussion and citations. The memory field also has its share of low-quality work; we hope our framework helps readers quickly judge and save time, rather than getting lost in a fog of jargon. At the same time, truly meaningful papers should receive the recognition they deserve.
Taxonomy at a Glance
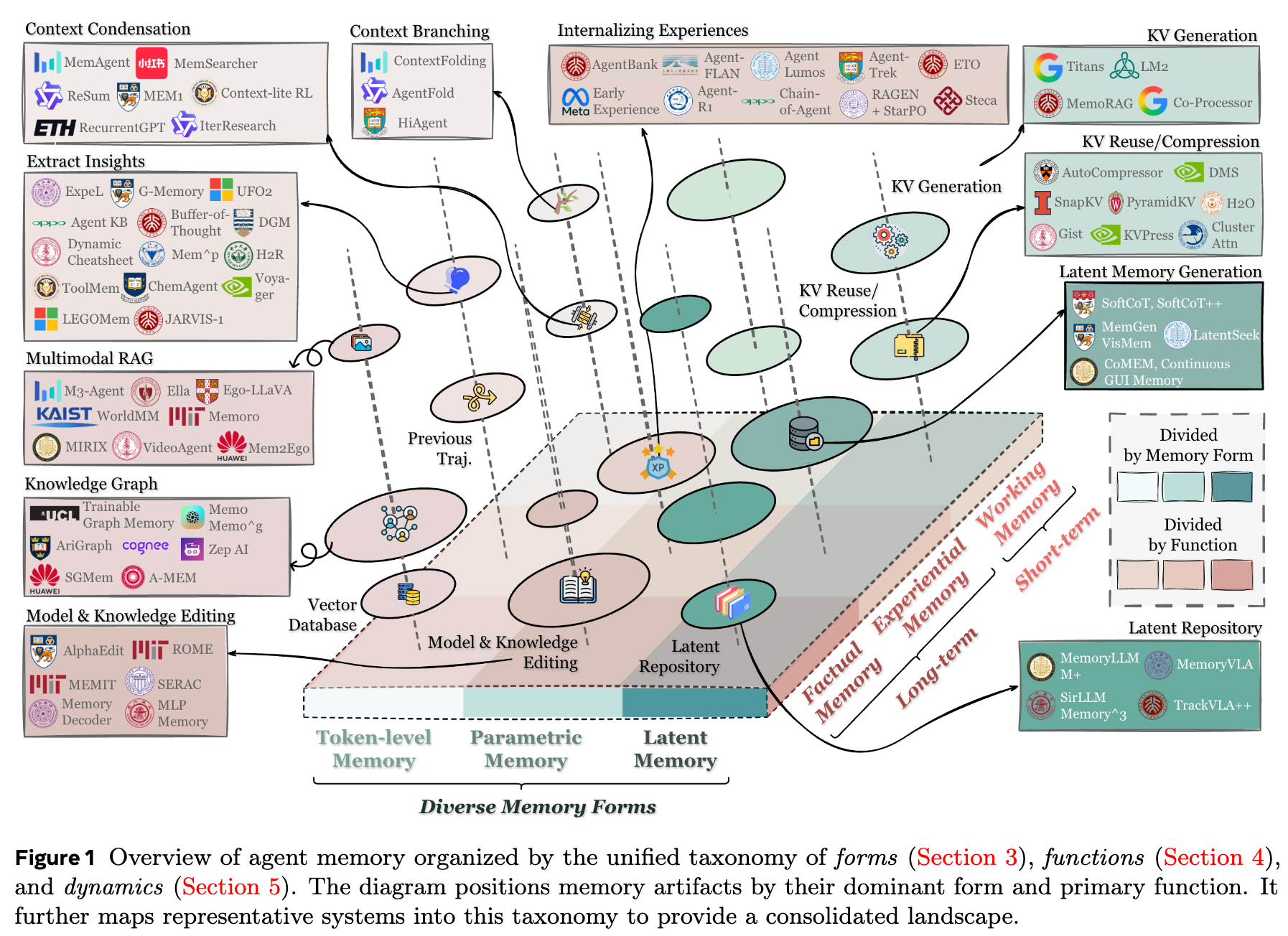
As the survey subtitle suggests, we define three coordinate axes for agent memory—three lenses:
- Form: the form of memory, concerning its architecture and representation.
- Function: the function of memory, indicating its responsibilities, purposes, and scenarios.
- Dynamic: the dynamics of memory, a high-level methodological abstraction describing how memory evolves over time.
The first two provide a fast way to locate where a memory work “sits,” making it easier to match with similar works and scenarios; together they form a 2D plane with nine quadrants. Dynamics adds a time dimension (the z-axis) that runs through all works, serving as a methodological template for understanding them. We expand on these three dimensions below.
Form

We categorize memory forms into three major types based on where memory is stored and how it is represented: token-level, parametric, and latent.
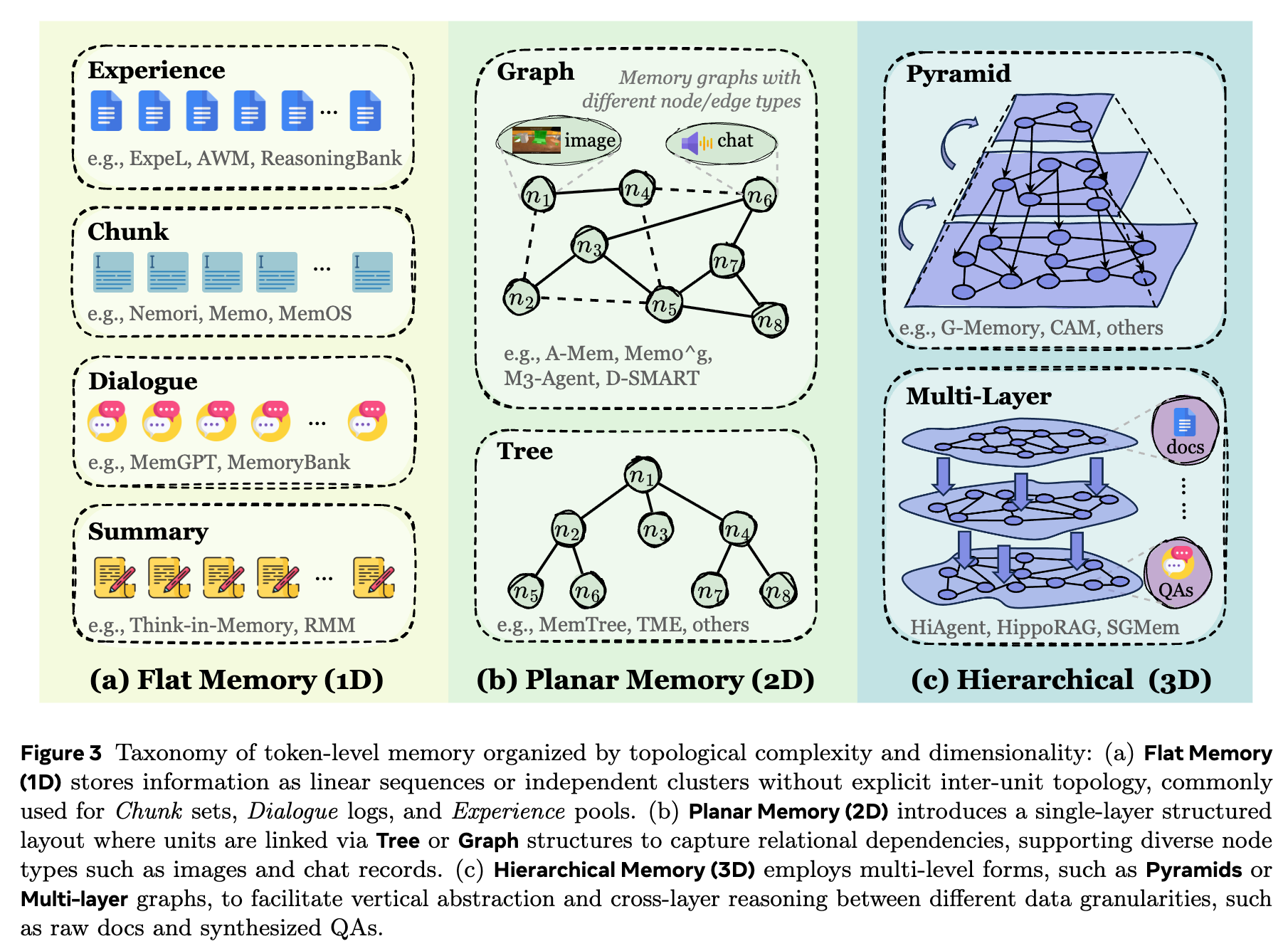
The core feature of token-level memory is that, at inference time, it can be fed into the model as discrete tokens via retrieval or other mechanisms. It is explicit, external, and plug-and-play. Some readers may wonder why we use a compound adjective. We considered descriptions like semantic or textual, but those seem less suitable for multimodal settings. If we simply call it external/explicit, then other types would all become internal/implicit by contrast. While this aligns with cognitive science to some extent, in agent memory it can feel like an over-simplified “one-cut-fits-all” symmetry. (If you have better naming suggestions after reading Section 3, feel free to contact us.)
Token-level memory is not limited to vocabulary tokens; it can also include discretized elements such as visual tokens and audio frames. This form is clear, editable, and interpretable, making it naturally compatible with computational operations like retrieval, storage, routing, and conflict resolution—hence it is the most studied and the most broadly explored. Depending on relationships among tokens, it can be organized into different structures such as 1D, 2D, and 3D layouts.

Parametric memory includes both internal and external parameters, where “internal vs. external” is defined with respect to a single base model.
- Internal parameters: tuning a model at different stages—pretraining, mid-training, or post-training—to introduce relevant knowledge and memory. This includes work on alignment and model editing.
- External parameters: for example, converting external documents into LoRA modules and injecting them at inference time to mitigate knowledge conflicts, or introducing other auxiliary parameter structures.
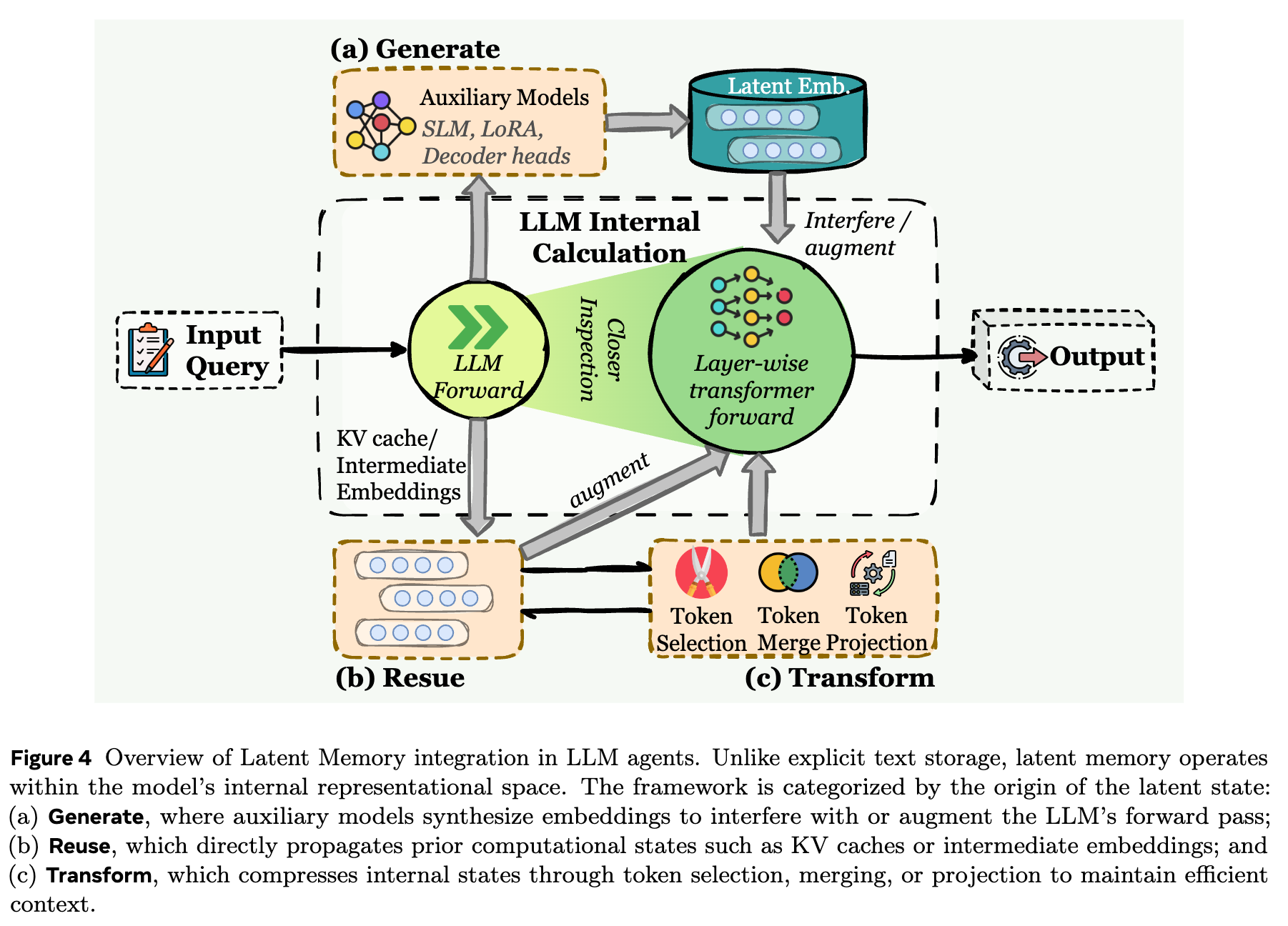
Latent memory has become particularly popular this year. It is an intermediate form between explicit tokens and fully parametric memory. Its core carrier is the latent token: a dense vector that compresses discrete memory content while preserving more contextual information. It is not human-readable, but it offers higher information density. We further categorize it by origin into three types: generate, reuse, and transform.
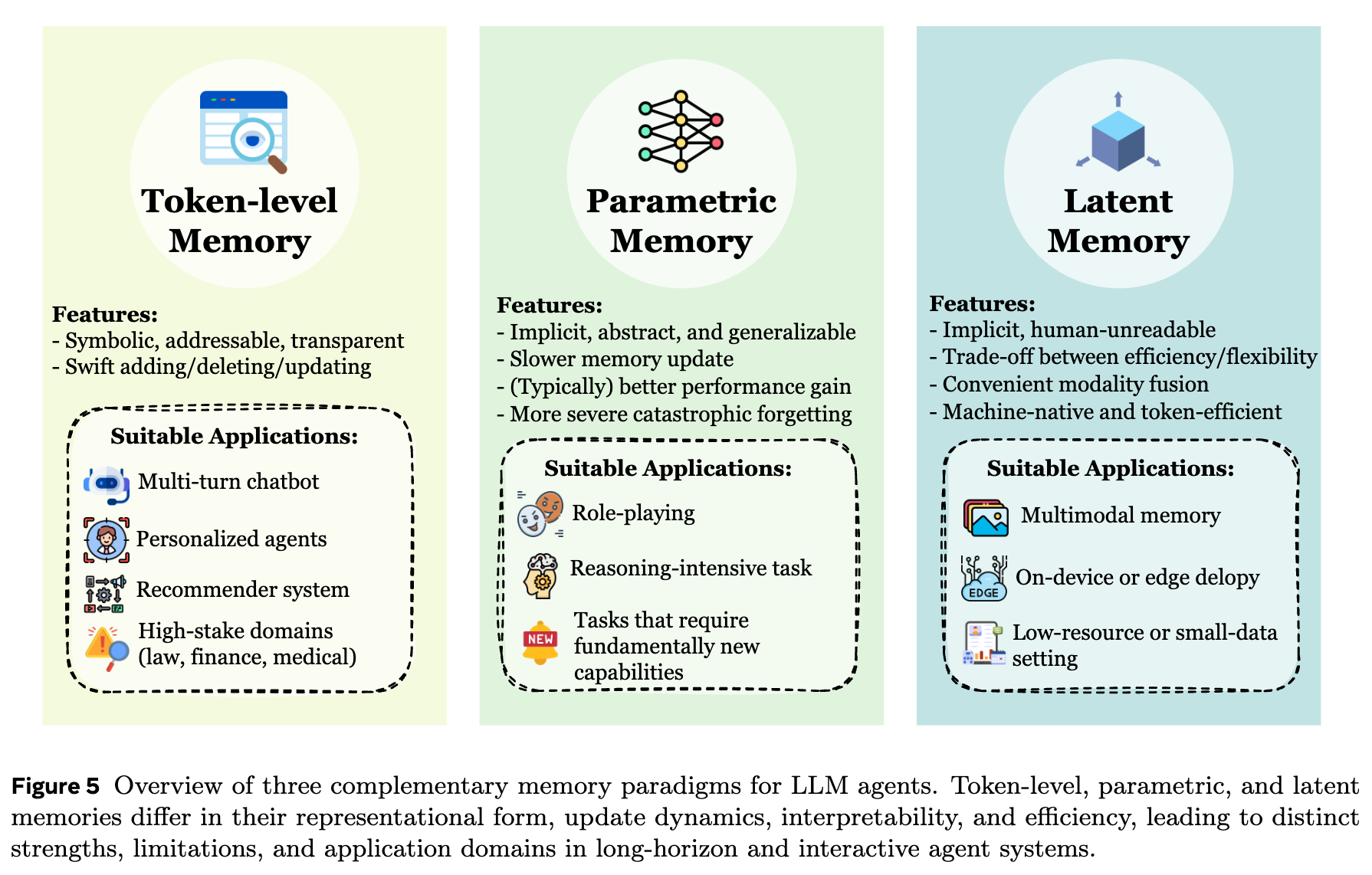
Finally, different memory forms have their own characteristics, strengths, and weaknesses. Importantly, no form is universally optimal; everything depends on the application scenario. We dedicate Section 3.4 to explaining how memory forms map to task settings.
Function
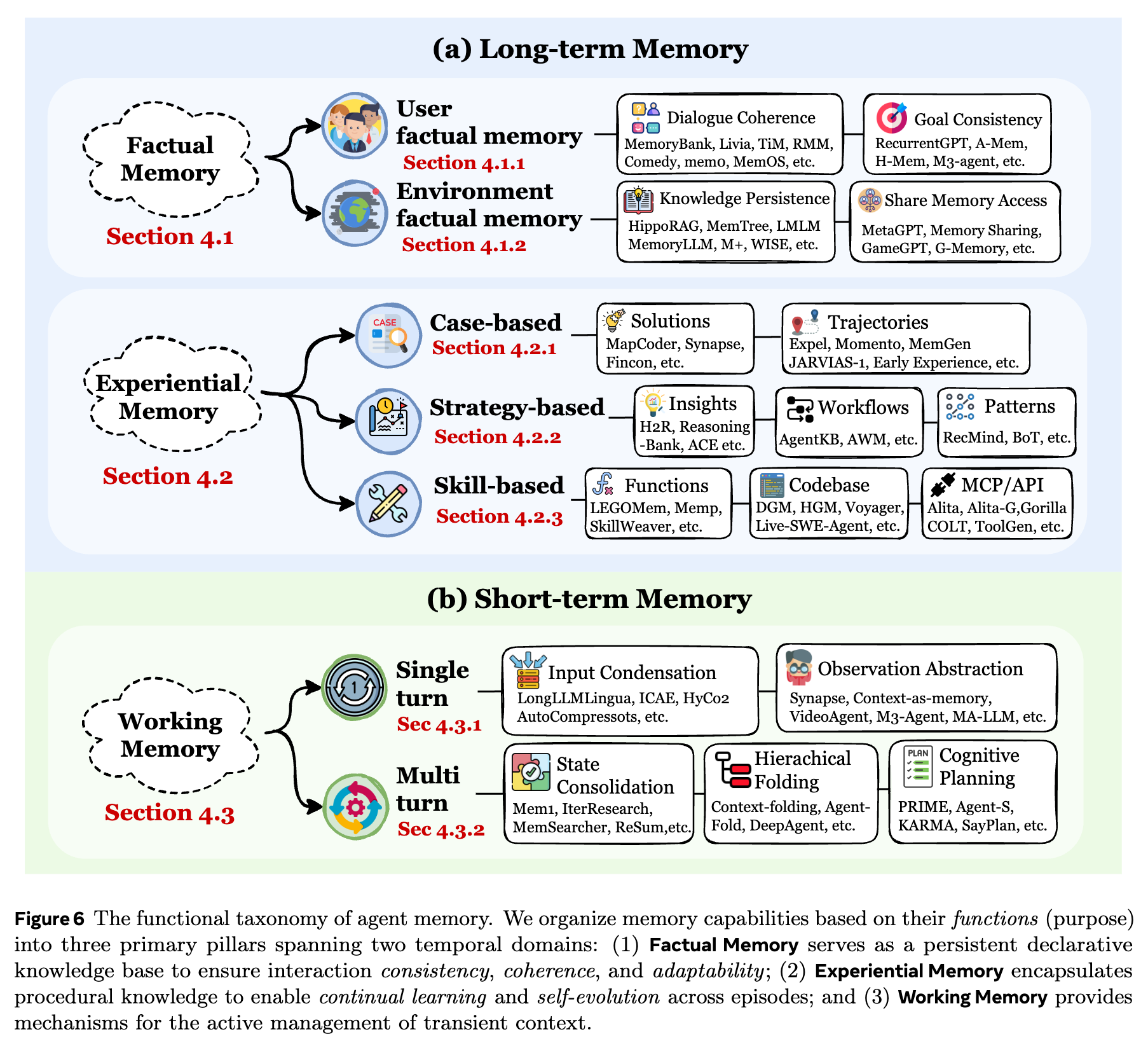
Memory functions fall into three scenarios: factual memory, experiential memory, and working memory. These correspond to different goals and capabilities. Many systems are designed to span multiple goals/scenarios rather than being mutually exclusive.
(Yes—some readers will complain again that the third name is not symmetric with the other two. The author also hasn’t found a better, widely accepted term yet…)

Factual memory covers dialogue history, user preferences, events, world knowledge, and so on. From the perspective of human memory, it roughly corresponds to episodic memory and semantic memory, but in agent memory these two can coexist rather than being opposed. Its purposes include consistency, coherence, and adaptability:
- Consistency: stability of behavior and self-presentation over time; avoiding contradictions and arbitrary stance shifts.
- Coherence: context awareness; maintaining topic continuity so responses form logically coherent dialogues.
- Adaptability: personalizing behavior based on stored user profiles and historical feedback, gradually aligning responses and decisions with a user’s specific needs and traits.
Because the content is extensive, we further divide factual memory into user factual memory and environment factual memory.
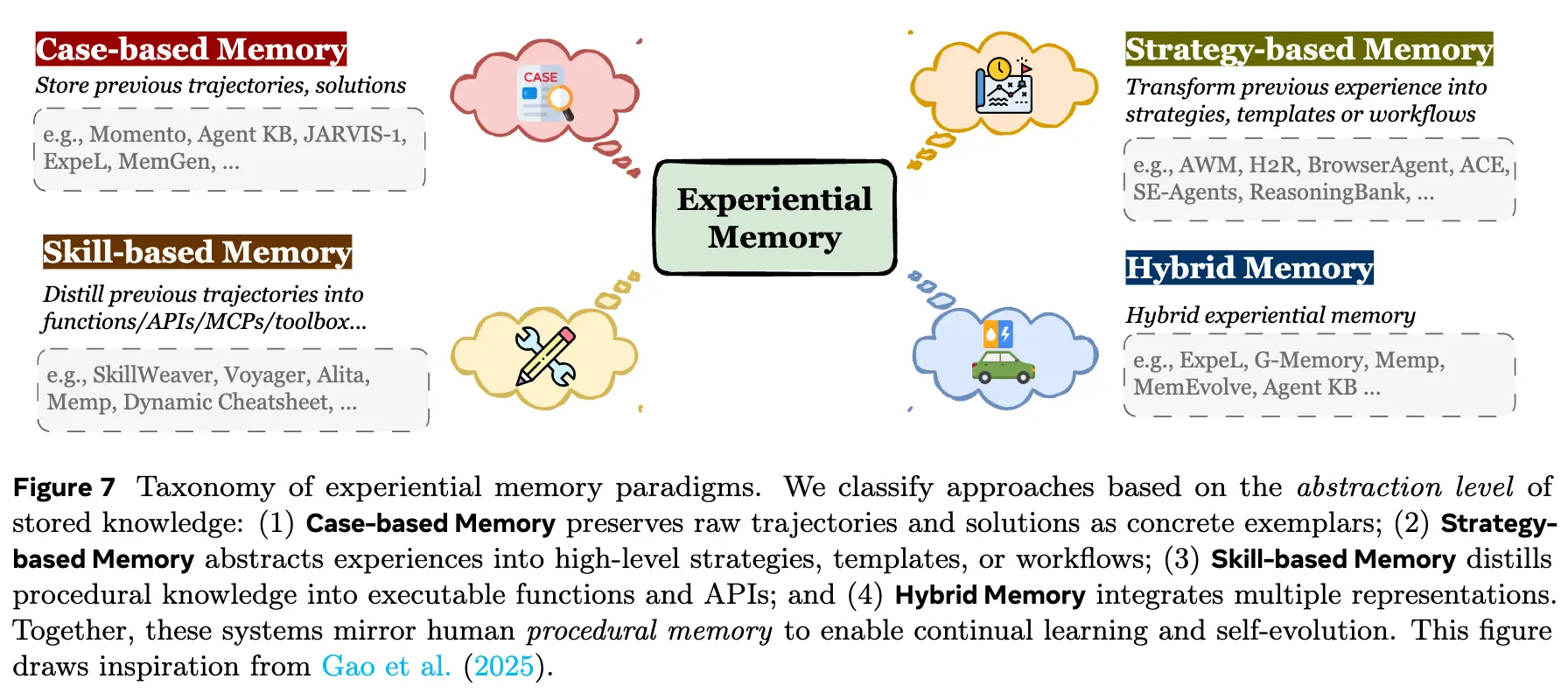
Experiential memory is strongly task-oriented: I have a difficult task—how can I do better next time? Therefore, it needs to store and organize historical trajectories, distilled strategies, and outcomes. Its goal is to enable continual learning and self-evolution for the agent. By maintaining a structured experience repository, an agent can follow a non-parametric adaptation path, avoiding the high cost of frequent parameter updates. By converting interaction feedback into reusable knowledge, it effectively closes the learning loop. We categorize it mainly into three types: case-based, strategy-based, and skill-based, plus hybrid designs that mix them.

Working memory operates within a single trial: it supports higher-order cognition by selecting, maintaining, and transforming task-relevant information on the fly. This is closest to the concept of working memory in cognitive science. We define it as an active management mechanism. Much of it overlaps with context engineering research topics, but strictly speaking, the concept of working memory was proposed earlier.
Its goal is to manage memory for long-horizon agentic tasks within a limited context window. This is not merely about “infinite context,” but about forgetting: what matters, what is redundant, and what must be written down for later lookup. In limited working memory, only the most important content is retained—so attention is not wasted on irrelevant tokens.
Dynamic
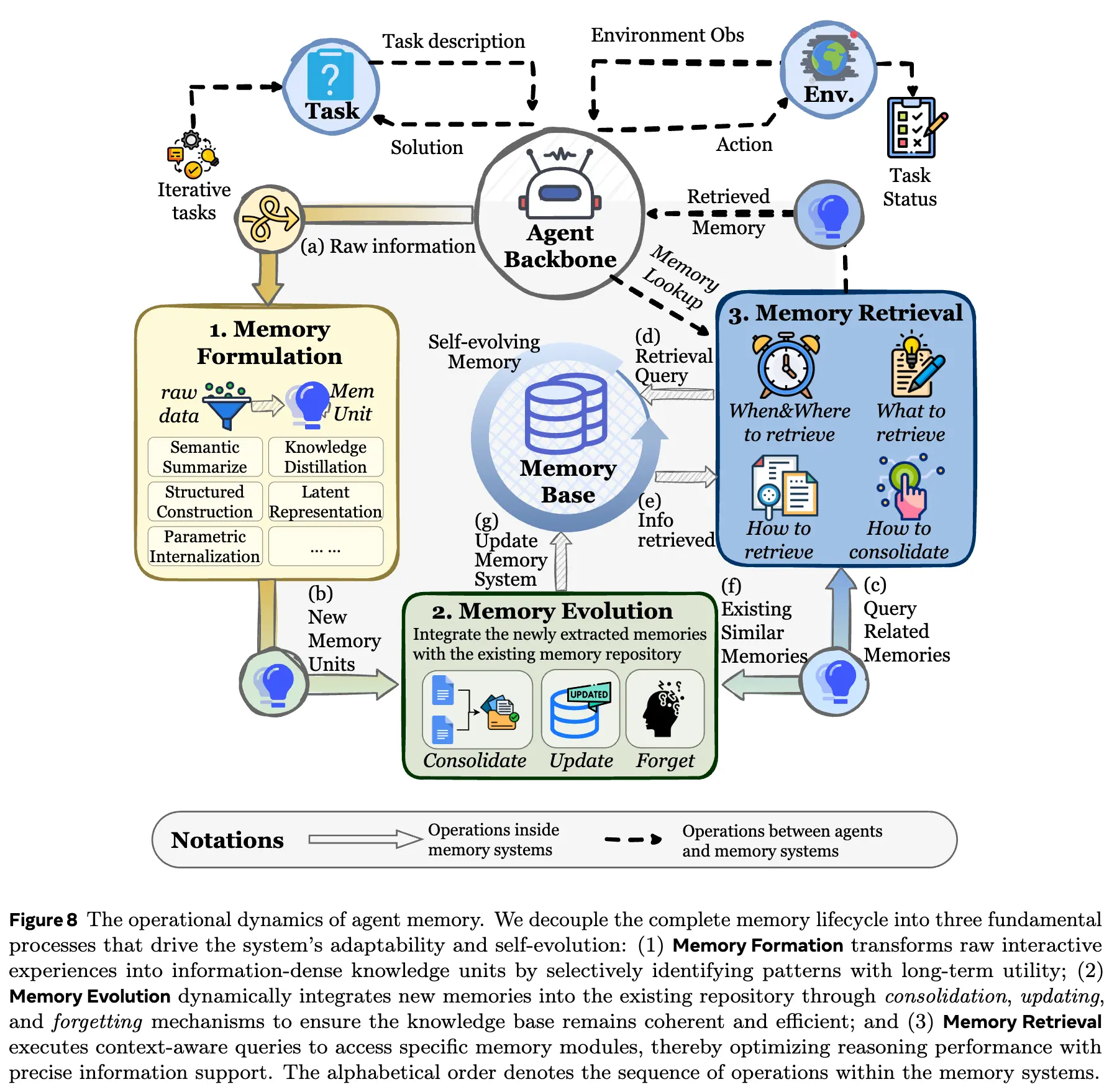
Memory dynamics covers the full lifecycle of memory—from “emergence” to “mission completion.” In an earlier blog post written around September, the author summarized the agent memory workflow as “acquire–organize–use.” Here we offer a more elegant expression: formulation–evolution–retrieval.
Dynamics is not a classification axis like the previous two; it is an epistemic lens that reduces most agent memory work into these three core processes, helping you quickly grasp the essence. These three processes are tightly coupled: designs for each part are not independent and must be considered jointly with the others.

Memory formulation emphasizes turning raw experience into information-dense knowledge (initial denoising), focusing on memory extraction and representation. It includes five major categories—this is one aspect that differentiates it from traditional LLM memory (“how to remember more”).
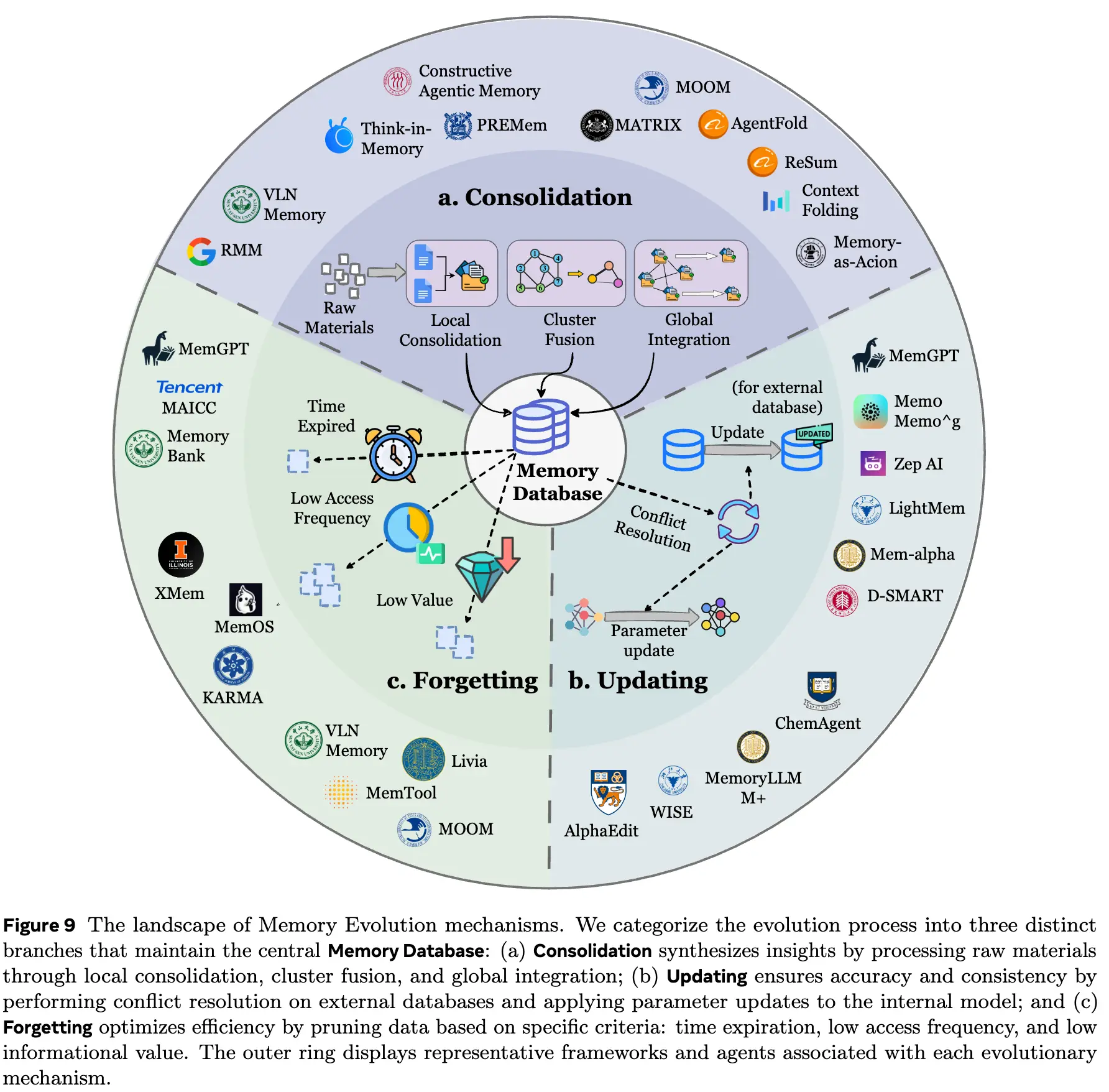
Memory evolution focuses on the organization and updating between memories: integrating new and old memories to synthesize higher-level insights, resolve logical conflicts, and remove outdated data. This also distinguishes it from static RAG.

Memory retrieval focuses on when to search, how to search, and post-processing. This is the final step before memory enters the next round of reasoning. If formulation and organization are done well but retrieval fails, the system is still one step short—so the three parts are a single whole. This is not merely “tool calling,” but a shift from static search to a dynamic cognitive process. Ideally, an agent coordinates these components within a unified pipeline, approximating human-like associative recall to enable efficient access.
Resources
We compiled benchmarks the community cares about for Memory / Lifelong / Self-Evolving Agents, as well as existing open-source memory frameworks and products, as references for readers.
Discussion
Here we list future goals and directions that we find interesting and promising; each already has some related work for reference:
- Memory Retrieval vs. Memory Generation: context-adaptive, multimodal, learnable
- Automatic memory management: breaking away from fixed workflows
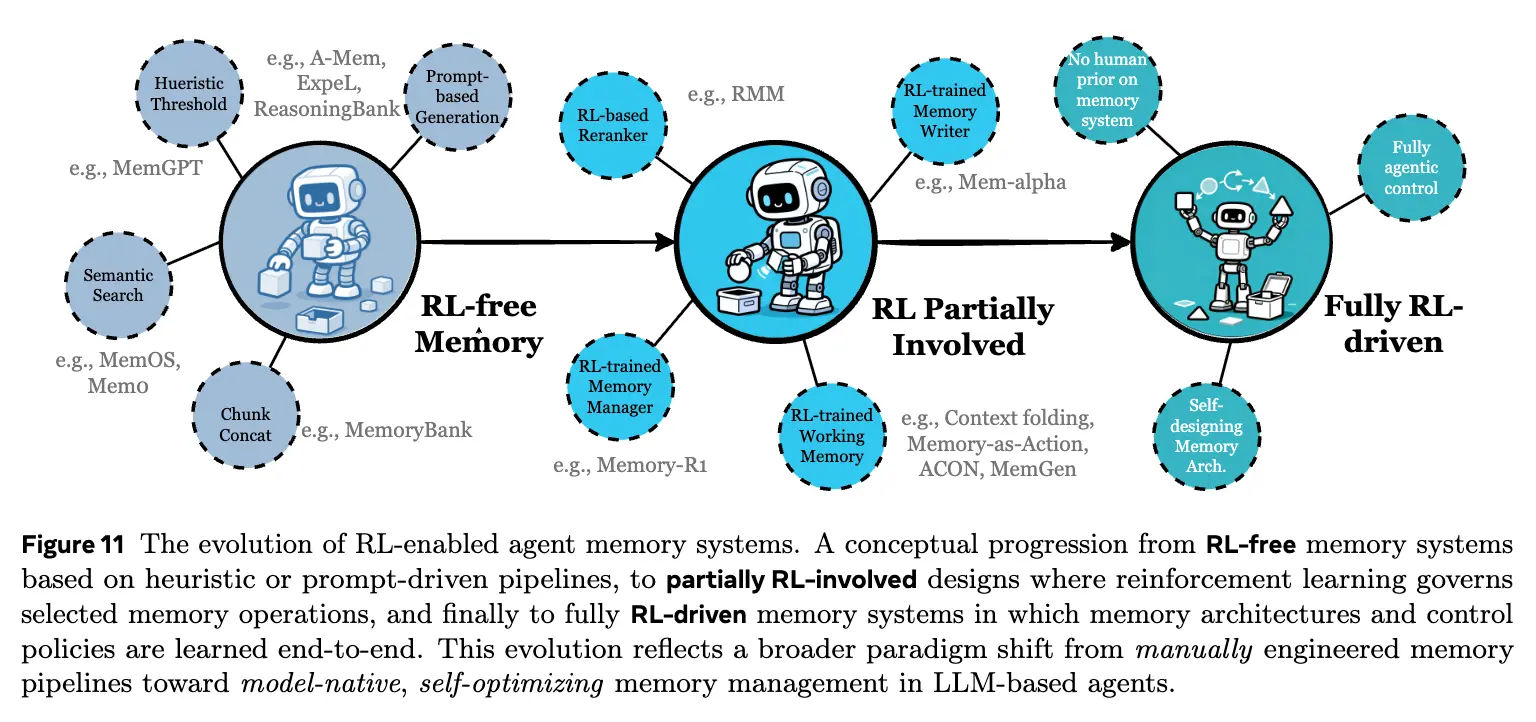
- RL-integrated memory design: which memory dynamics can RL govern, and how to gradually remove unnecessary priors
- Multimodal memory: from multimodal to omni-modal
- Shared memory in multi-agent systems: how to communicate across heterogeneous agents
- World models: how memory can assist world modeling
- Trustworthy memory: the security and verifiability of memory itself
- Human-like memory: in which aspects it still differs from human memory
Story
Unlike traditional lab-based collaboration and communication, the four core authors of this work were connected purely online: we met because of posts on Xiaohongshu. We are all new graduate students from the 2024–2025 cohort, with similar academic backgrounds, ages, and interests—and we immediately clicked.
Guibin Zhang served as the leading organizer, demonstrating exceptional leadership, decisiveness, and deep insight—absolutely among the best peers I have met. Yuyang Hu and Yanwei Yue are likewise outstanding researchers, doers, and thinkers; our discussions were filled with intense intellectual collisions and sparks of inspiration. Co-authors, senior PhDs, and faculty who participated treated this work with seriousness, rigor, and responsibility. We hope our final result can live up to the (somewhat) ambitious goals we set at the very beginning.
From the first meeting to final submission, this survey took roughly two months. Our division of labor was clear; communication was smooth; coordination was tight; and we iterated at high frequency. In the new era, cross-university, cross-organization, and cross-institution collaborations will become increasingly frequent and common. We believe that shared academic goals and interests are the strongest glue—and that truly enduring academic ideals will ultimately cross oceans and connect the world.