 RedNote
RedNote
I’m currently a Master’s degree student (from September 2024) at the School of Computer Science of Fudan University and a member of the FudanNLP Lab, co-advised by Prof. Xuanjing Huang (黄萱菁) and Associate Prof. Tao Gui(桂 韬). Previously, I got my bachelor’s degree in June 2024 from Fudan University, advised by Associate Prof. Tao Gui.
My previous research focused on model reasoning and reward modeling, and I am currently concentrating on agent memory. Feel free to reach out via email✉️ or RedNote (小红书) — I’m always open to academic discussions of any kind! 👏🏻
🔥 News
- 2026.01: 🎉🎉 OctoBench (benchmark for scaffold-aware instruction following in agentic coding) is released on arXiv!
- 2025.12: 🎉🎉 Our comprehensive survey on Memory in the Age of AI Agents is released on arXiv!
- 2025.09: 🎉🎉 POLAR and Evalearn are accepted by NeurIPS 2025!
- 2025.07: 🎉🎉 Our paper on Reward Model Pre-training, POLAR, is now available on
!
- 2024.05: 🎉🎉 One paper on math reasoning & RL was accepted by ICML-2024!
- 2024.03: 🎉🎉 One paper on in-context learning was accepted by NAACL-2024-Findings!
- 2023.12: 🎉🎉 One paper on evaluation was accepted by AAAI-2024!
💻 Internships
 2025.3 - Present · Algorithm Researcher, NEX-AGI (Shanghai Qiji Zhifeng Co., Ltd.), Shanghai
2025.3 - Present · Algorithm Researcher, NEX-AGI (Shanghai Qiji Zhifeng Co., Ltd.), Shanghai
Agent memory and context management 2025.1 - 2025.3 · LLM Center, Shanghai AI Laboratory, Shanghai
2025.1 - 2025.3 · LLM Center, Shanghai AI Laboratory, Shanghai
Generalist Reward Modeling · Mentors: Yicheng Zou, Qipeng Guo 2024.8 - 2024.12 · ByteDance AI Lab Research, Shanghai
2024.8 - 2024.12 · ByteDance AI Lab Research, Shanghai
Proactive Agent · Mentor: Wei Li- 2023.12 - 2024.3 · General Safety Group, Shanghai AI Laboratory, Shanghai
LLM Agent · Mentors: Jing Shao, Tao Gui
📝 Publications
L3-Agent
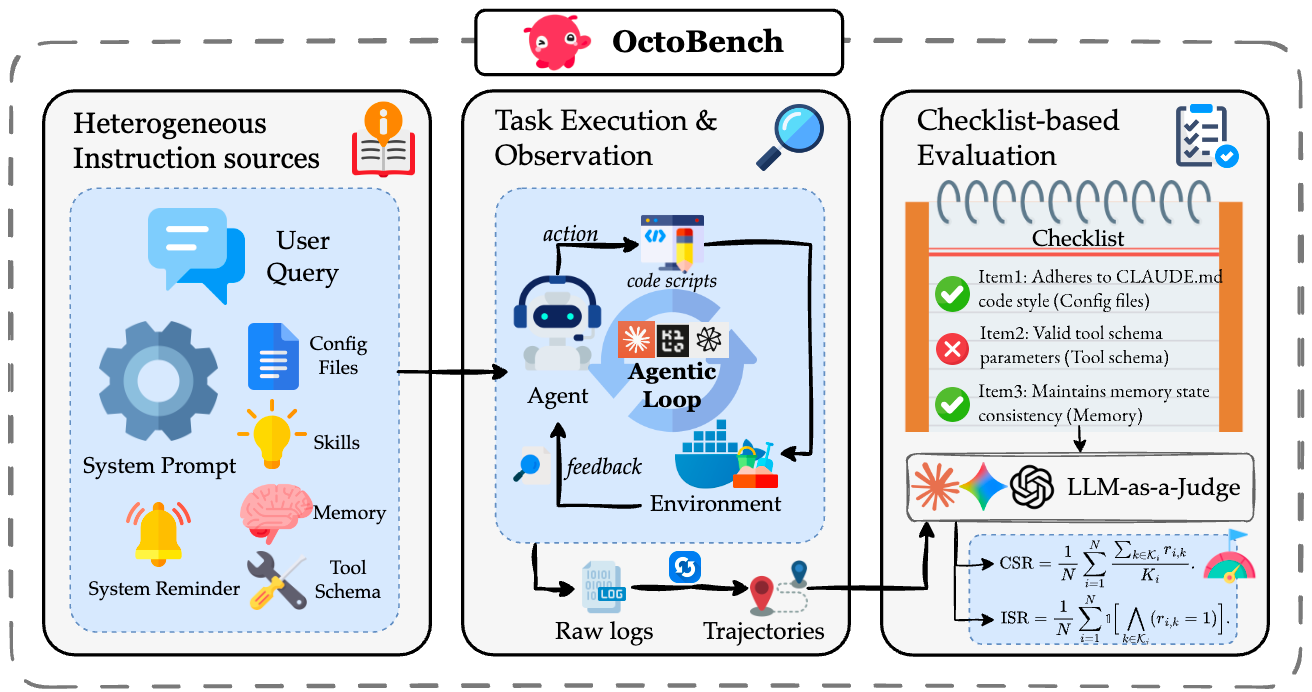
OctoBench: Benchmarking Scaffold-Aware Instruction Following in Repository-Grounded Agentic Coding
Deming Ding*, Shichun Liu*, Enhui Yang*, Jiahang Lin*, Ziying Chen, Shihan Dou, Honglin Guo, Weiyu Cheng, Pengyu Zhao, Chengjun Xiao, Qunhong Zeng, Qi Zhang, Xuanjing Huang, Qidi Xu, Tao Gui
- Modern coding scaffolds turn LLMs into capable software agents, but their ability to follow scaffold-specified instructions remains under-examined. OctoBench benchmarks scaffold-aware instruction following in repository-grounded agentic coding.
- OctoBench includes 34 environments and 217 tasks under three scaffold types, with 7,098 objective checklist items. We release an automated observation-and-scoring toolkit for full trajectories and fine-grained checks.
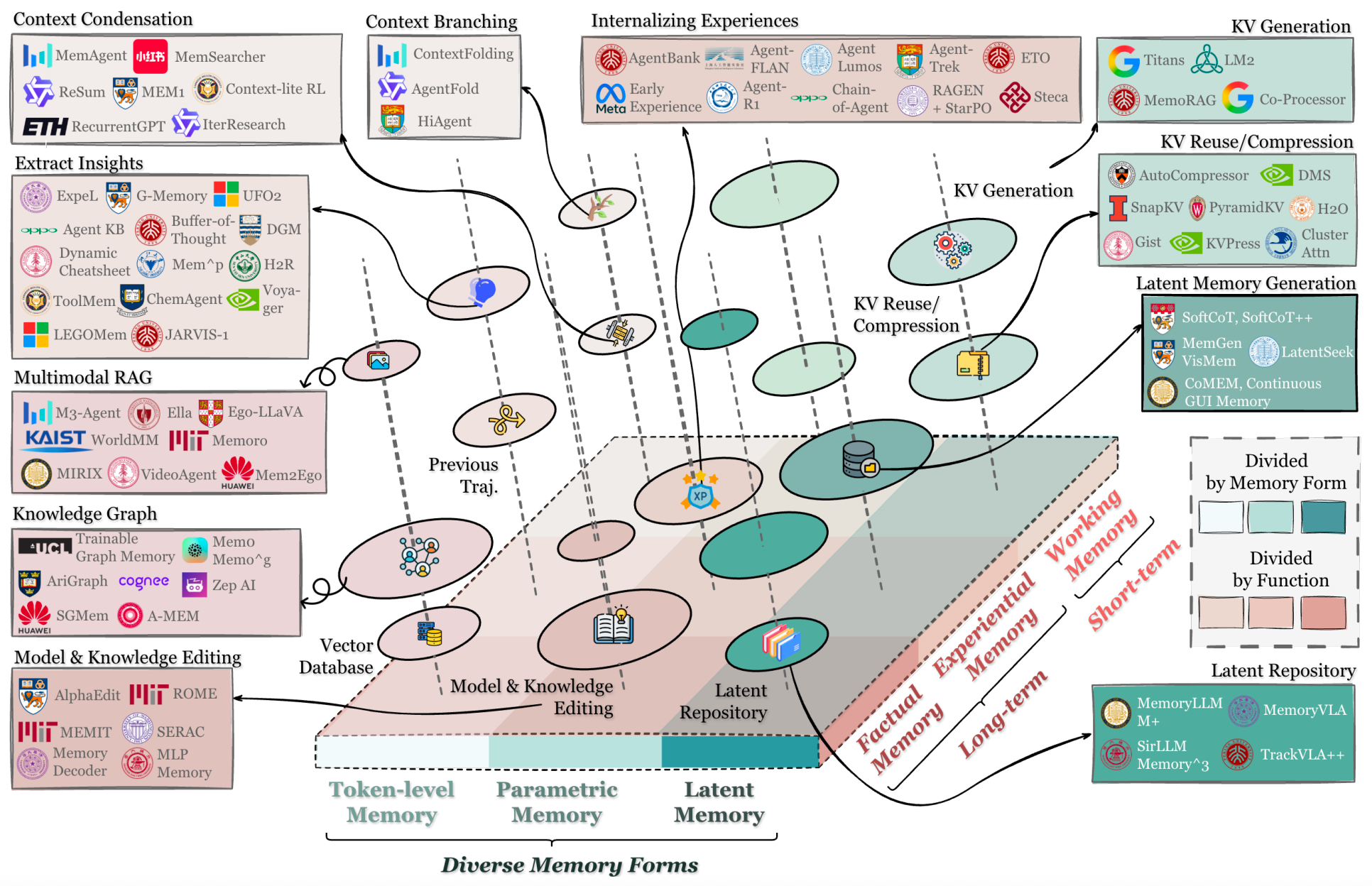
Memory in the Age of AI Agents: A Survey
Yuyang Hu†, Shichun Liu†, Yanwei Yue†, Guibin Zhang†, etc.
†Core Contributors with Names Listed Alphabetically.
- Memory serves as the cornerstone of foundation model-based agents, underpinning their ability to perform long-horizon reasoning, adapt continually, and interact effectively with complex environments.
- We provide a comprehensive overview through three unified lenses: Forms, Functions, and Dynamics.
|
|
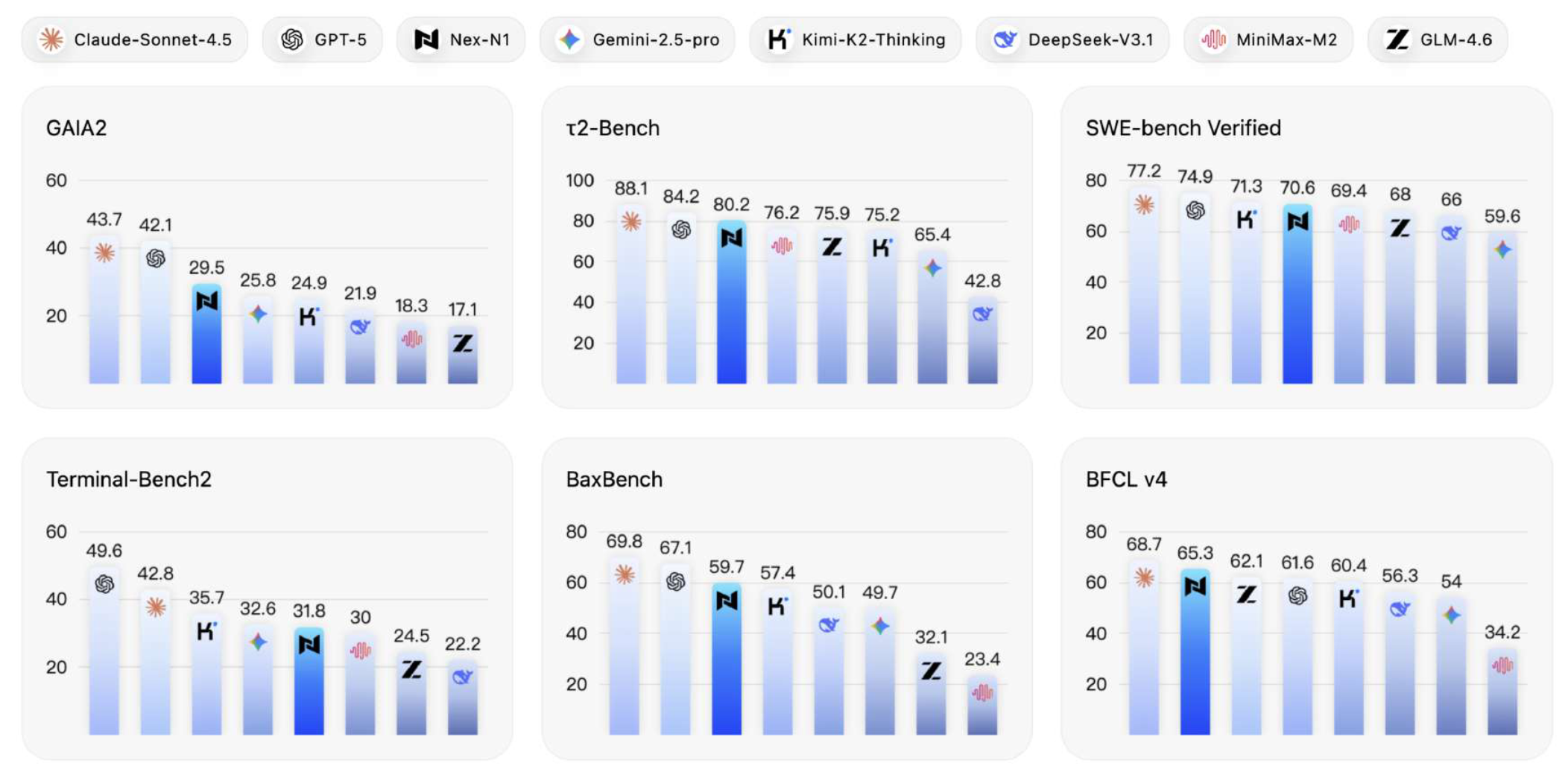
Nex-N1: Agentic Models Trained via a Unified Ecosystem for Large-Scale Environment Construction
Nex-AGI Team: Yuxuan Cai, Lu Chen, …, Shichun Liu, …, Xuanjing Huang, Xipeng Qiu
- We introduce a comprehensive method designed to systematically scale the diversity and complexity of interactive environments through three orthogonal dimensions: Complexity (NexAU), Diversity (NexA4A), and Fidelity (NexGAP).
- Nex-N1 consistently outperforms SOTA open-source models and achieves competitive performance against frontier proprietary models on complex agentic tasks (SWE-bench, tau2).
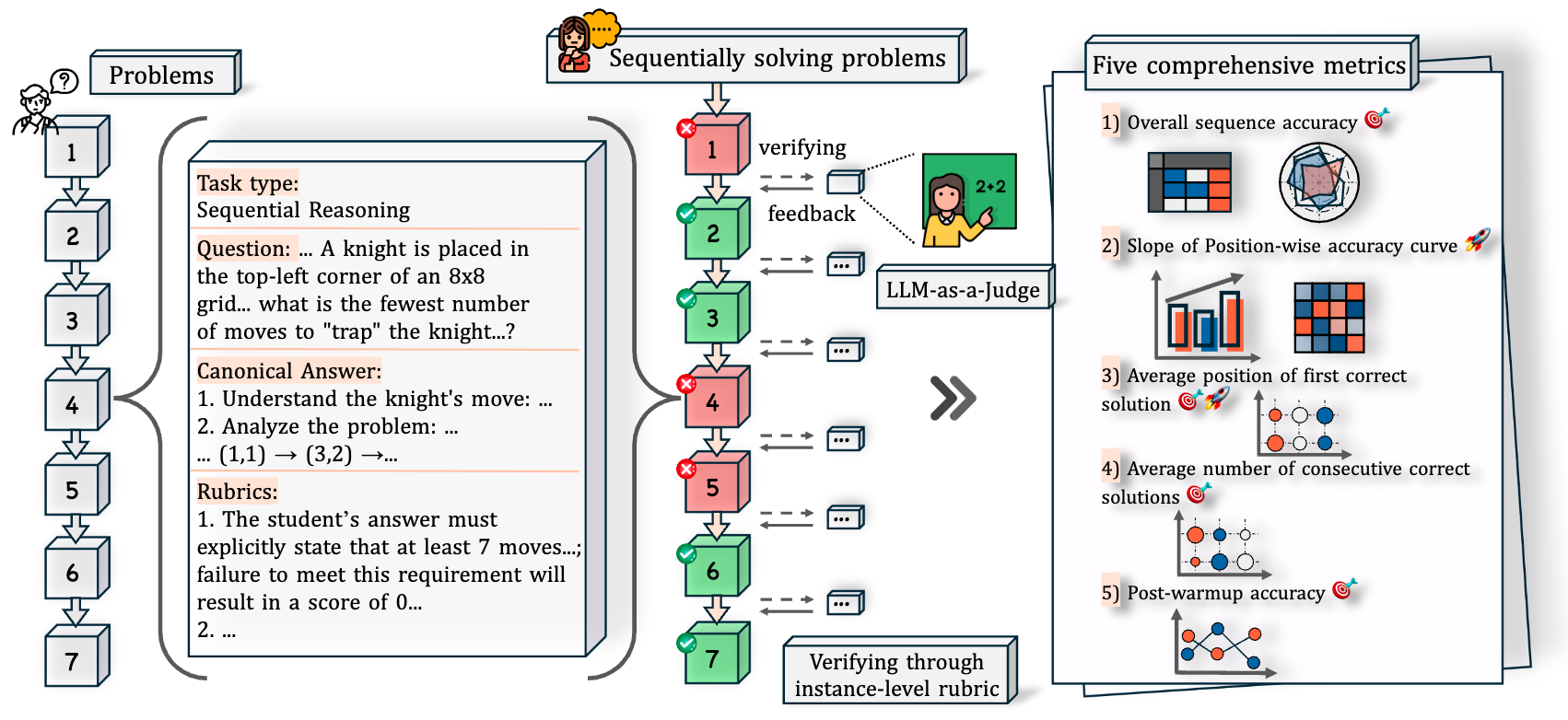
EvaLearn: Quantifying the Learning Capability and Efficiency of LLMs via Sequential Problem Solving
Shihan Dou, Ming Zhang, Chenhao Huang, Jiayi Chen, Feng Chen, Shichun Liu, Yan Liu, Chenxiao Liu, Cheng Zhong, Zongzhang Zhang, Tao Gui, Chao Xin, Wei Chengzhi, Lin Yan, Qi Zhang, Yonghui Wu, Xuanjing Huang
- We introduce EvaLearn, a benchmark to evaluate the learning capability of LLMs through sequential problem-solving, where models learn from prior experience.
- It features 648 problems in 182 sequences and five metrics, revealing that static ability doesn’t always correlate with learning capability, thus offering a new dimension for model evaluation.
L2-Reasoner
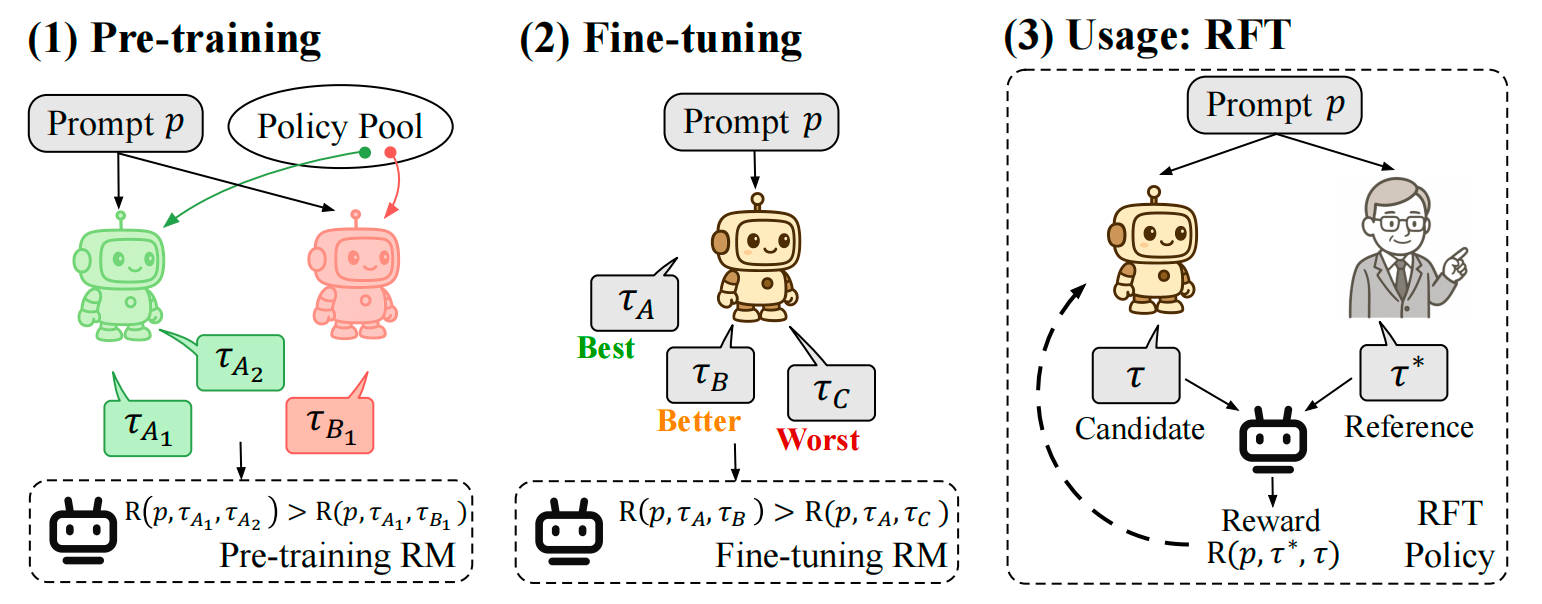
POLAR: Pre-Trained Policy Discriminators are General Reward Models
Shihan Dou*‡, Shichun Liu*‡, Yuming Yang*, Yicheng Zou*†, Yunhua Zhou, Shuhao Xing, Chenhao Huang, Qiming Ge, Demin Song, Haijun Lv, Songyang Gao, Chengqi Lv, Enyu Zhou, Honglin Guo, Zhiheng Xi, Wenwei Zhang, Qipeng Guo, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Tao Gui†, Kai Chen†
*Equal contributions. †Corresponding authors. ‡Work done during an internship at Shanghai AI Laboratory.
- Say goodbye to reward models with poor generalization! POLAR (Policy Discriminative Learning) is a groundbreaking pre-training paradigm that trains reward models to distinguish policy distributions, eliminating heavy reliance on human preference data!
- Highly scalable and tailored for Reinforcement Fine-tuning (RFT)! POLAR assigns rewards based on ground truths, seamlessly integrating into the RFT framework and significantly reducing reward hacking across general tasks!
|
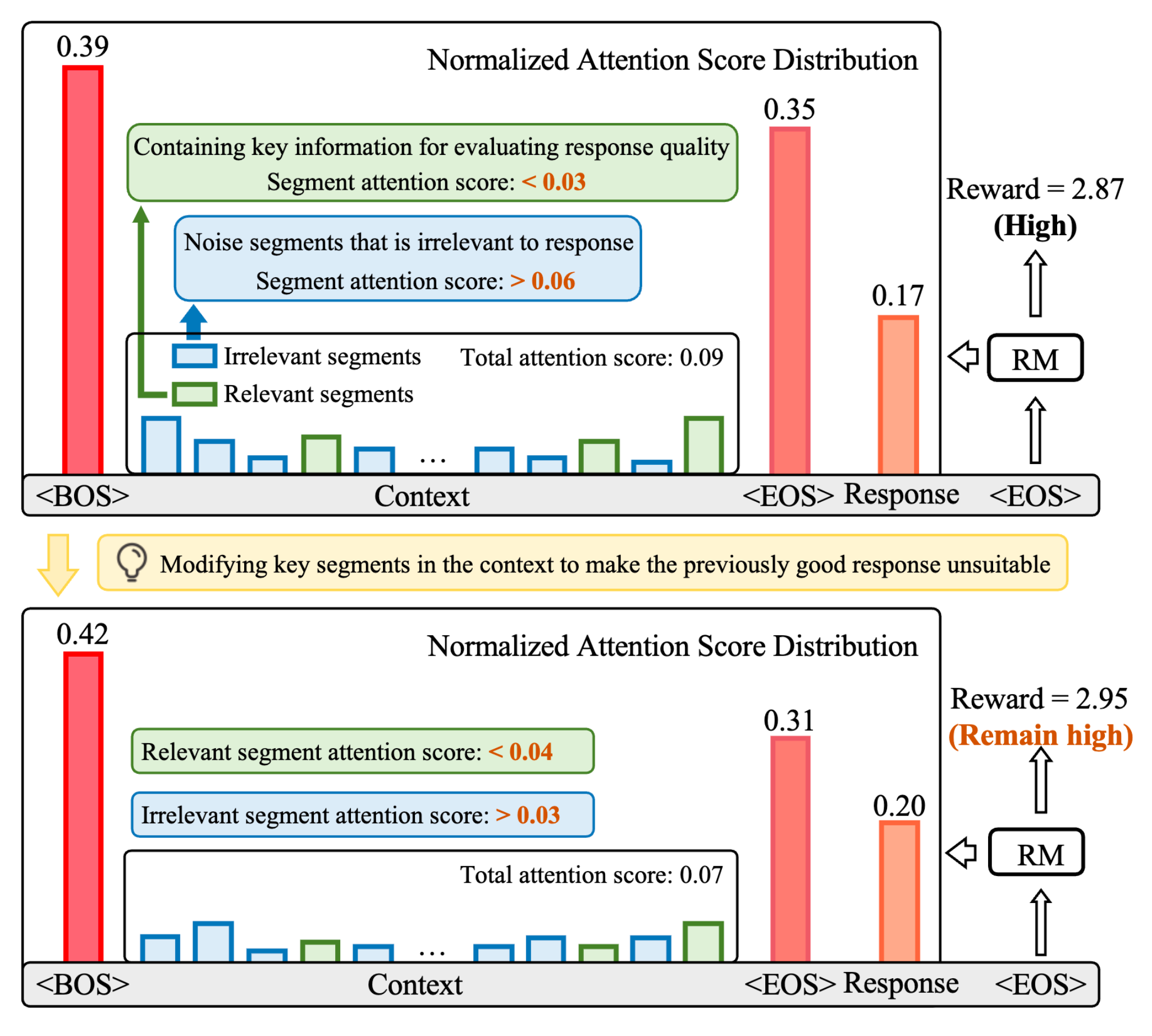
Lost in the Context: Insufficient and Distracted Attention to Contexts in Preference Modeling
Shihan Dou*, Jiayi Chen*, Chenhao Huang*, Feng Chen, Wei Chengzhi, Huiyuan Zheng, Shichun Liu, Yan Liu, Chenxiao Liu, Chao Xin, Lin Yan, Zongzhang Zhang, Tao Gui, Qi Zhang, Xuanjing Huang
- The reward model (RM) in RLHF often overlooks crucial context, leading to poor preference alignment. We find that the RM allocates insufficient attention to the context and ignores relevant segments.
- To address this, we propose AttnRM, a novel optimization framework that directs the RM’s focus to important contextual information. Experimental results show that AttnRM significantly enhances preference modeling, generalizability, and alignment with human preferences.
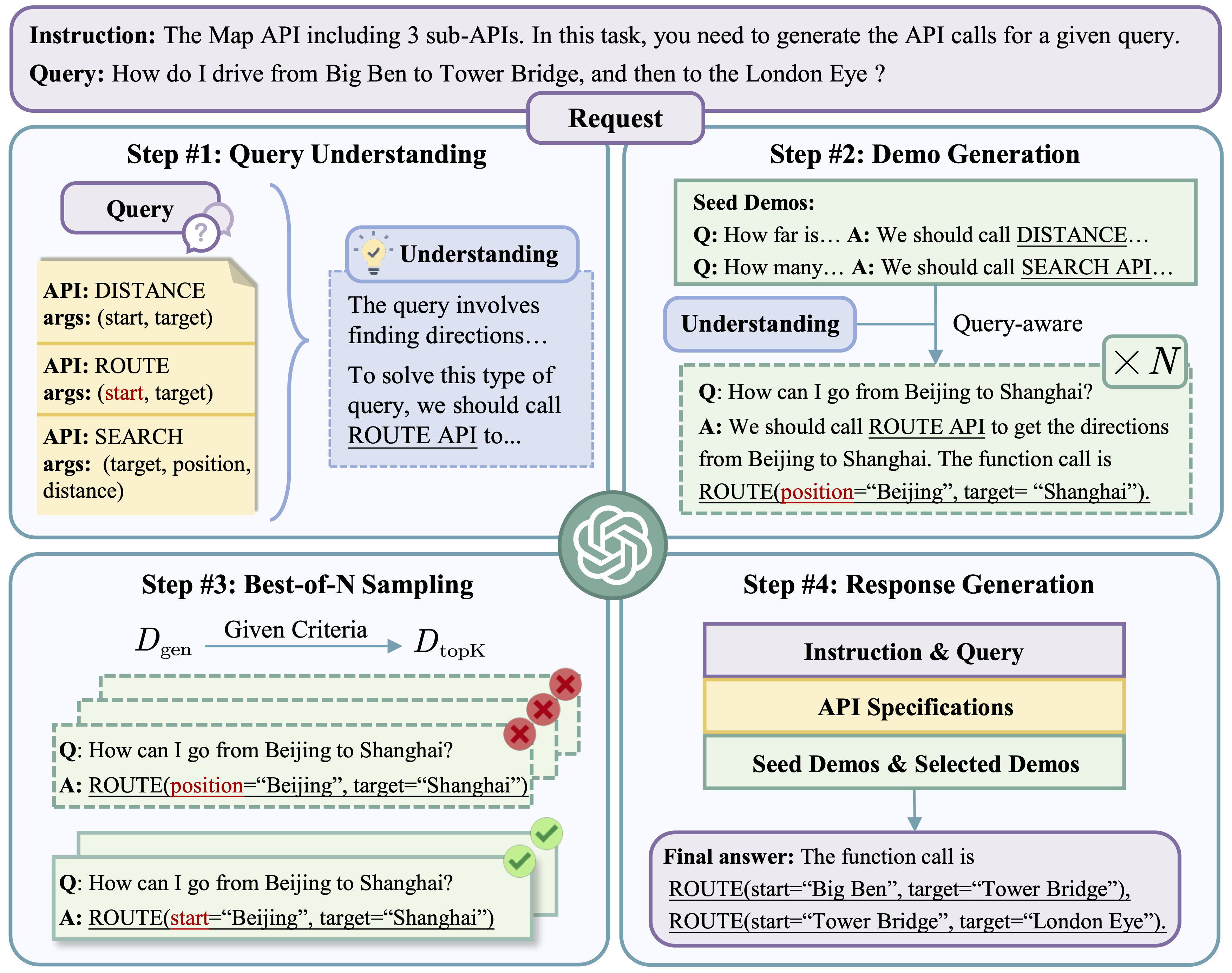
Self-Demos: Eliciting Out-of-Demonstration Generalizability in Large Language Models
Wei He, Shichun Liu, Jun Zhao, Yiwen Ding, Yi Lu, Zhiheng Xi, Tao Gui, Qi Zhang, Xuanjing Huang.
- Goal: develop a method that can enhance the generalizability of LLMs when encountering OOD queries, allowing them to better adapt to novel tasks.
- Through extensive experiments on the tool-using scenario (OOD-Toolset) and mathematical problem-solving tasks (GSM8K and MATH datasets), SELF-DEMOS demonstrated superior performance in handling OOD queries compared to existing state-of-the-art methods.
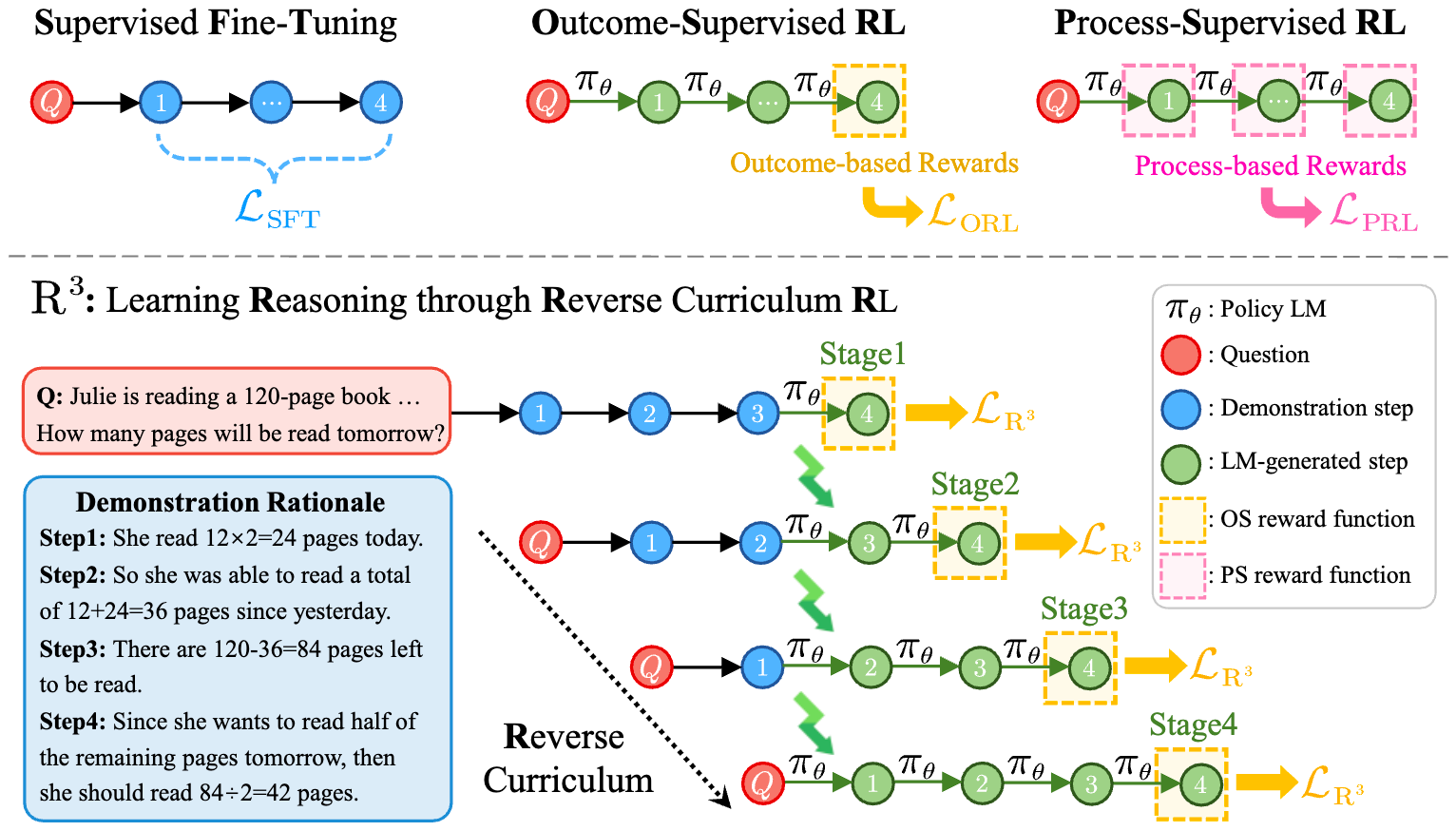
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
Zhiheng Xi*, Wenxiang Chen*, Boyang Hong*, Senjie Jin*, Rui Zheng, Wei He, Yiwen Ding, Shichun Liu, Xin Guo, Junzhe Wang, Honglin Guo, Wei Shen, Xiaoran Fan, Yuhao Zhou, Shihan Dou, Xiao Wang, Xinbo Zhang, Peng Sun, Tao Gui, Qi Zhang, Xuanjing Huang
- We propose R3, a novel method that achieves the benefits of process supervision using only outcome supervision. R3 learns reasoning via a reverse curriculum, progressively moving from easy to hard tasks and enabling precise, step-level feedback.
- Our method surpasses RL baselines on eight reasoning tasks by 4.1 points on average, and with CodeLlama-7B, it performs comparably to much larger models without extra data.
L1-Chatbot

LLMEval: A Preliminary Study on How to Evaluate Large Language Models
Yue Zhang*, Ming Zhang*, Haipeng Yuan, Shichun Liu, Yongyao Shi, Tao Gui, Qi Zhang, Xuanjing Huang
- Addresses the crucial “how to evaluate” question for LLMs, analyzing various criteria, scoring methods, and ranking systems.
- Introduces the LLMEval dataset, based on evaluations of 20 LLMs with over 240,000 manual annotations, and offers 10 key insights for future evaluation.
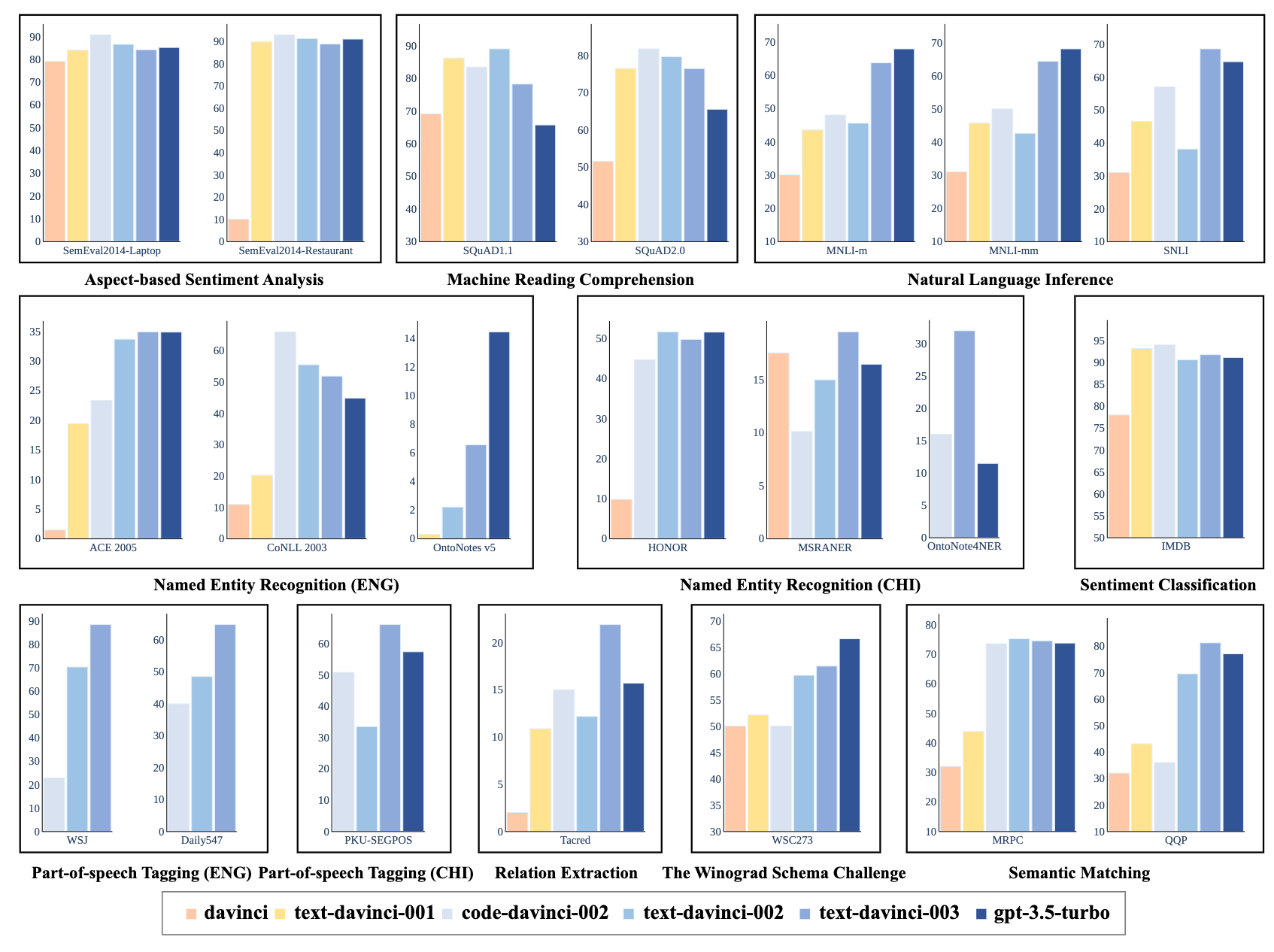
A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models
Junjie Ye*, Xuanting Chen*, Nuo Xu, Can Zu, Zekai Shao, Shichun Liu, Yuhan Cui, Zeyang Zhou, Chao Gong, Yang Shen, Jie Zhou, Siming Chen, Tao Gui, Qi Zhang, Xuanjing Huang
- We analyze the capability evolution of six GPT-3 and GPT-3.5 models on 21 NLU datasets.
- Our findings reveal that model capabilities do not uniformly improve with evolution, as strategies like RLHF can sometimes compromise performance on specific tasks while enhancing others.
🎖 Honors and Awards
- 2024.06,the Top Students Award in Computer Science in recognition of his exceptional academic performance in the National Top Talent Undergraduate Training Program.
- 2022.09, the First prize (Top 0.6% of 49242 teams) of Contemporary Undergraduate Mathematical Contest in Modeling (CUMCM).
- 2021.12, the Second Prize of the Scholarship for Outstanding Students at Fudan University in the 2020-2021 academic year.
- 2021.12, the Second Prize Winner(Non-Physics A) in the 38th National Physics Competition for College Students.
- 2021.12, 2022.12, the Second Prize Winner(Non-Math) in the 13, 14th National Mathematics Competition for College Students.
📖 Educations
- 2020.9 - 2024.6, B.E. at Fudan University with a major in computer science and technology.
💡Services
- Reviewer of ACL, NeurIPS.